
Před čtením tohoto článku doporučujeme pochopit, co je to neuronová síť. V procesu Sestavování neuronové sítě je jednou z možností, kterou dostanete na výběr, jakou aktivační funkci použít ve skryté vrstvě i ve výstupní vrstvě sítě. Tento článek se zabývá některými z těchto voleb.
Elementy neuronové sítě :-
Vstupní vrstva :- Tato vrstva přijímá vstupní funkce. Poskytuje síti informace z vnějšího světa, v této vrstvě se neprovádějí žádné výpočty, uzly zde pouze předávají informace(funkce) skryté vrstvě.
Skrytá vrstva :- Uzly této vrstvy nejsou vystaveny vnějšímu světu, jsou součástí abstrakce, kterou poskytuje každá neuronová síť. Skrytá vrstva provádí všechny druhy výpočtů na funkcích zadaných prostřednictvím vstupní vrstvy a výsledek přenáší do výstupní vrstvy.
Výstupní vrstva :- Tato vrstva přináší informace naučené sítí do vnějšího světa.
Co je aktivační funkce a proč je používat?
Definice aktivační funkce:- Aktivační funkce rozhoduje, zda má být neuron aktivován, nebo ne, a to tak, že vypočítá vážený součet a dále k němu přidá zkreslení. Účelem aktivační funkce je vnést do výstupu neuronu nelinearitu.
Vysvětlení :-
Víme, že neuronová síť má neurony, které pracují v souladu s váhou, zkreslením a jejich příslušnou aktivační funkcí. V neuronové síti bychom aktualizovali váhy a zkreslení neuronů na základě chyby na výstupu. Tento proces je znám jako zpětné šíření. Aktivační funkce umožňují zpětné šíření, protože k aktualizaci vah a předpětí jsou dodávány gradienty spolu s chybou.
Proč potřebujeme nelineární aktivační funkce :-
Nervová síť bez aktivační funkce je v podstatě jen lineární regresní model. Aktivační funkce provádí nelineární transformaci vstupu, díky čemuž je schopna se učit a provádět složitější úlohy.
Matematický důkaz :-
Předpokládejme, že máme neuronovou síť takto :-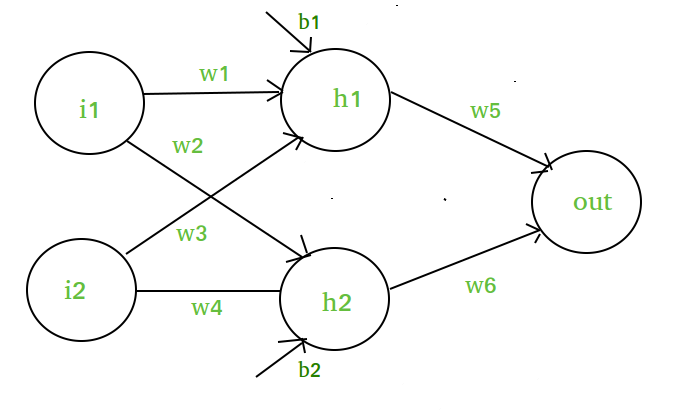
Elementy diagramu :-
Skrytá vrstva tj. vrstva 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Zde
- z(1) je vektorizovaný výstup vrstvy 1
- W(1) jsou vektorizované váhy přiřazené neuronům
skryté vrstvy i.tj. w1, w2, w3 a w4- X jsou vektorizované vstupní funkce, tj. i1 a i2
- b je vektorizované zkreslení přiřazené neuronům skryté
vrstvy, tj. b1 a b2- a(1) je vektorizovaný tvar libovolné lineární funkce.
(Poznámka: Neuvažujeme zde aktivační funkci)
Vrstva 2, tj. výstupní vrstva :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Výpočet ve výstupní vrstvě:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Toto pozorování vede opět k lineární funkci i po použití skryté vrstvy, proto můžeme konstatovat, že nezáleží na tom, kolik skrytých vrstev v neuronové síti připojíme, všechny vrstvy se budou chovat stejně, protože složení dvou lineárních funkcí je samo o sobě lineární funkcí. Neuron se nemůže učit pouze s připojenou lineární funkcí. Nelineární aktivační funkce mu umožní učit se podle rozdílu s chybou.
Proto potřebujeme aktivační funkci.
VARIANTY AKTIVAČNÍ FUNKCE :-
1). Lineární funkce :-
- Rovnice : Lineární funkce má podobnou rovnici jako přímka, tj. y = ax
- Nezáleží na tom, kolik máme vrstev, pokud jsou všechny lineární povahy, výsledná aktivační funkce poslední vrstvy není nic jiného než právě lineární funkce vstupu první vrstvy.
- Rozsah : -inf až +inf
- Použití : Lineární aktivační funkce se používá pouze na jednom místě, tj.Tj. výstupní vrstvě.
- Problémy : Pokud budeme diferencovat lineární funkci, abychom do ní vnesli nelinearitu, výsledek již nebude záviset na vstupu „x“ a funkce se stane konstantní, nezavede to do našeho algoritmu žádné převratné chování.
Příklad : Výpočet ceny domu je regresní problém. Cena domu může mít libovolně velkou/malou hodnotu, takže na výstupní vrstvě můžeme použít lineární aktivaci. I v tomto případě musí mít neuronová síť ve skrytých vrstvách libovolnou nelineární funkci.
2). Sigmoidní funkce :-
- Jedná se o funkci, která se vykresluje jako graf ve tvaru písmene „S“.
- Rovnice :
A = 1/(1 + e-x) - Povaha : Nelineární. Všimněte si, že hodnoty X leží mezi -2 až 2, hodnoty Y jsou velmi strmé. To znamená, že malé změny v x by vyvolaly také velké změny v hodnotě Y.
- Rozsah hodnot : 0 až 1
- Použití : Obvykle se používá ve výstupní vrstvě binární klasifikace, kde je výsledek buď 0, nebo 1, protože hodnota pro sigmoidní funkci leží pouze mezi 0 a 1, takže lze snadno předpovědět, že výsledek bude 1, pokud je hodnota větší než 0,5, a 0 v opačném případě.
3). Funkce Tanh :- Aktivace, která funguje téměř vždy lépe než sigmoidní funkce, je funkce Tanh známá také jako tangentní hyperbolická funkce. Je to vlastně matematicky posunutá verze sigmoidní funkce. Obě jsou si podobné a lze je od sebe odvodit.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Rozsah hodnot :- -1 až +1
- Povaha :- nelineární
- Použití :- Obvykle se používá ve skrytých vrstvách neuronové sítě, protože její hodnoty leží mezi -1 až 1, tudíž střední hodnota pro skrytou vrstvu vychází 0 nebo velmi blízko ní, tudíž pomáhá při centrování dat tím, že střední hodnotu přiblíží 0. To usnadňuje učení další vrstvy.
- Rovnice :- A(x) = max(0,x). Dává výstup x, pokud je x kladné, a 0 v opačném případě.
- Rozsah hodnot :- [0, inf)
- Povaha :- nelineární, což znamená, že můžeme snadno zpětně šířit chyby a mít více vrstev neuronů aktivovaných funkcí ReLU.
- Použití :- ReLu je výpočetně méně náročná než tanh a sigmoid, protože zahrnuje jednodušší matematické operace. Najednou je aktivováno jen několik neuronů, takže síť je řídká, což ji činí efektivní a snadnou pro výpočet.
4). RELU :- Označuje rektifikovanou lineární jednotku. Jedná se o nejpoužívanější aktivační funkci. Implementuje se hlavně ve skrytých vrstvách neuronové sítě.
Zjednodušeně řečeno, RELU se učí mnohem rychleji než sigmoidní a Tanh funkce.
5). Funkce Softmax :- Funkce Softmax je také typem sigmoidní funkce, ale hodí se, když se snažíme zpracovat klasifikační problémy.
- Povaha :- nelineární
- Použití :- Obvykle se používá, když se snažíme zpracovat více tříd. Funkce softmax by stlačila výstupy pro každou třídu mezi 0 a 1 a také by dělila součtem výstupů.
- Výstup:- Funkce softmax se ideálně používá ve výstupní vrstvě klasifikátoru, kde se vlastně snažíme dosáhnout pravděpodobnosti pro určení třídy každého vstupu.
- Základní pravidlo zní: Pokud opravdu nevíte, jakou aktivační funkci použít, pak jednoduše použijte RELU, protože je to obecná aktivační funkce a v dnešní době se používá ve většině případů.
- Pokud je vaším výstupem binární klasifikace, pak je sigmoidní funkce velmi přirozenou volbou pro výstupní vrstvu.
VYBRÁNÍ SPRÁVNÉ AKTIVAČNÍ FUNKCE
Poznámka :-
Aktivační funkce provádí nelineární transformaci vstupu, díky čemuž je schopna se učit a provádět složitější úlohy.