
Přestože je příkaz find bezpochyby jedním z nejoblíbenějších a nejvýkonnějších nástrojů příkazového řádku pro vyhledávání souborů v Linuxu, není dostatečně rychlý pro situace, kdy potřebujete okamžité výsledky. Pokud chcete vyhledat soubor v systému prostřednictvím příkazového řádku a rychlost je pro vás nejvyšší prioritou, pak můžete použít jiný příkaz:
V tomto tutoriálu probereme příkaz locate na snadno pochopitelných příkladech. Upozorňujeme, že všechny zde uvedené pokyny/příklady byly testovány v Ubuntu 16.04 LTS a verze příkazu locate, kterou jsme použili, je 0.26.
Jak používat příkaz locate v Linuxu
Příkaz locate se používá velmi snadno. Stačí mu předat název souboru, který chcete vyhledat.
locate
Pokud chci například vyhledat všechny názvy souborů, které mají v sobě řetězec ‚dir2‘, pak to mohu provést pomocí příkazu locate následujícím způsobem:

Poznámka: Příkaz ‚locate dir2‘ (bez hvězdiček) bude také stačit, protože locate implicitně nahradí předaný název (řekněme NAME) za *NAME*.
Jak funguje příkaz locate, aneb, proč je tak rychlý
Důvodem, proč je příkaz locate tak rychlý, je to, že nečte souborový systém pro hledaný název souboru nebo adresáře. Ve skutečnosti se odkazuje na databázi (připravenou příkazem updatedb), aby našel, co uživatel hledá, a na základě tohoto hledání vytváří svůj výstup.
Ačkoli je tento přístup dobrý, má i své nevýhody. Hlavní problém spočívá v tom, že po každém vytvoření nového souboru nebo adresáře v systému je třeba aktualizovat databázi nástroje, aby správně fungoval. Jinak příkaz nebude schopen najít soubory/adresáře, které byly vytvořeny po poslední aktualizaci databáze.
Pokusím-li se například najít soubory s názvy obsahujícími řetězec ‚tosearch‘ v adresáři ‚Downloads‘ v mém systému, příkaz find poskytne na výstupu jeden výsledek:

Ale když se pokusím provést stejné vyhledávání pomocí příkazu locate, neposkytne žádný výstup.
![]()
To znamená, že databáze locate, ve které se vyhledává, nebyla po vytvoření souboru v systému aktualizována. Aktualizujme tedy databázi, což lze provést pomocí příkazu updatedb. Zde je návod, jak to udělat:
sudo updatedb
A když nyní spustím stejný příkaz locate znovu, ve výstupu se zobrazí soubory:
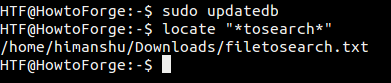
Podobně po odstranění souboru nebo adresáře se musíte ujistit, že databáze locate byla aktualizována, protože jinak bude příkaz při vyhledávání tento soubor ve svém výstupu zobrazovat i nadále.
Jak přimět příkaz locate, aby na výstupu vypsal počet nebo číslo odpovídajících záznamů
Jak jsme viděli, příkaz locate na výstupu vypisuje názvy odpovídajících souborů spolu s jejich úplnými nebo absolutními cestami. Pokud však chcete, můžete nástroj přimět k tomu, aby všechny tyto informace potlačil a místo nich vypsal pouze číslo nebo počet odpovídajících záznamů. To lze provést pomocí volby příkazového řádku -c.

Jak přinutit příkaz locate, aby vypisoval pouze ty položky, které odpovídají existujícím souborům
Jak jsme již uvedli dříve v tomto článku, pokud je soubor ze systému odstraněn, pak dokud znovu neaktualizujete databázi locate, bude příkaz ve výstupu nadále zobrazovat název tohoto souboru. Pro tento konkrétní případ však můžete vynechat aktualizaci databáze a přesto mít na výstupu správné výsledky pomocí volby -e příkazového řádku.
Příklad jsem ze systému odstranil soubor ‚filetosearch.txt‘. To potvrdil příkaz find, který již nebyl schopen soubor vyhledat:

Ale když jsem stejnou operaci provedl pomocí příkazu locate, soubor se ve výstupu stále zobrazoval:

A víme proč – protože databáze příkazu locate nebyla po odstranění souboru aktualizována. Pomocí volby -e se to však podařilo:
![]()
Tady se o této volbě píše v manuálové stránce locate: „
Jak zařídit, aby příkaz locate ignoroval rozdíly mezi velkými a malými písmeny
Ve výchozím nastavení je vyhledávací operace, kterou příkaz locate provádí, citlivá na velikost písmen. Pomocí volby -i příkazového řádku však můžete nástroj přinutit, aby ignoroval rozdíly velkých a malých písmen.
Příklad mám v systému dva soubory pojmenované ‚newfiletosearch.txt‘ a ‚NEWFILETOSEARCH.txt‘. Jak tedy vidíte, jména souborů jsou stejná, jen se liší jejich pády. Pokud požádáte příkaz locate, aby vyhledal, řekněme, „*tosearch*“, pak se ve výstupu zobrazí pouze název s malými písmeny:

Použití volby -i příkazového řádku však donutí příkaz ignorovat velikost písmen a ve výstupu se zobrazí oba názvy souborů:

Jak oddělit výstupní záznamy pomocí ASCII NUL
Ve výchozím nastavení jsou výstupní záznamy, které vytváří příkaz locate, odděleny pomocí znaku nového řádku (\n). Pokud však chcete, můžete oddělovač změnit a místo nového řádku použít znak ASCII NUL. To lze provést pomocí volby -0 příkazového řádku.
Například jsem spustil stejný příkaz, který jsme použili v minulé části výše, ale přidal jsem volbu -0 příkazového řádku:

Takže vidíte, že oddělovač nového řádku už tam není – byl nahrazen NUL.
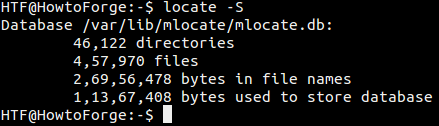
Jak zobrazit informace o databázi locate
V případě, že chcete vědět, kterou databázi locate používá, a další statistiky o databázi, použijte volbu příkazového řádku -S.
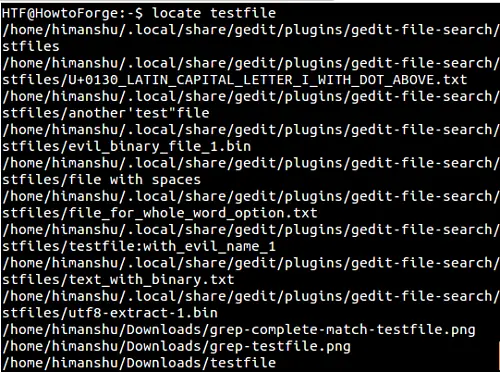
Jak vyhledat přesný název souboru pomocí příkazu locate
Ve výchozím nastavení, když hledáte název souboru pomocí příkazu locate, pak je předaný název – například NAME – implicitně nahrazen *NAME*. Pokud například vyhledám název souboru ‚testfile‘, pak se ve výstupu objeví všechny názvy odpovídající *testfile*:
Ale co když je požadavek vyhledat soubory s názvy přesně odpovídajícími ‚testfile‘? No, v tomto případě budete muset použít regulární výrazy, které lze povolit pomocí volby -r příkazového řádku. Zde je tedy návod, jak můžete pomocí regulárních výrazů vyhledat právě ‚testfile‘:
locate -r /testfile$

Pokud s regulárními výrazy začínáte, zamiřte sem.
Závěr
Locate nabízí mnohem více možností, ale ty, které jsme zde probrali, by vám měly stačit pro základní představu o nástroji příkazového řádku i pro začátek. Doporučujeme vám nejprve vyzkoušet všechny zde popsané možnosti na vašem linuxovém počítači a poté přejít na další, které najdete v manuálové stránce nástroje
.