

Začínáme-li Data miningem, nově zdokonaleným přístupem, který se dá úspěšně použít při predikci dat, jedná se o příznivou metodu používanou při analýze dat k objevování trendů a souvislostí v datech, které by mohly vyvolat skutečné zásahy.
Některé populární nástroje provozované v Data miningu jsou umělé neuronové sítě(ANN), logistická regrese, diskriminační analýza a rozhodovací stromy.
Rozhodovací strom je nejznámější a nejsilnější nástroj, který je snadno pochopitelný a rychle implementovatelný pro objevování znalostí z obrovských a složitých datových souborů.
Úvod
Řada teoretiků i praktiků techniky pravidelně přepracovává, aby byl proces přísnější, adekvátnější a nákladově efektivnější.
Původně se rozhodovací stromy používaly v teorii rozhodování a statistice ve velkém měřítku. Jsou také přesvědčivými nástroji v Data miningu, vyhledávání informací, text miningu a rozpoznávání vzorů ve strojovém učení.
Tady bych doporučil přečíst si můj předchozí článek, abyste se zastavili a zbystřili svůj fond znalostí, pokud jde o rozhodovací stromy.
Podstata rozhodovacích stromů převažuje v rozdělení datových souborů na jejich části, které nepřímo vytvářejí rozhodovací strom (obrácený), který má kořenové uzly na vrcholu. Vrstevnatý model rozhodovacího stromu vede ke konečnému výsledku prostřednictvím průchodu přes uzly stromů.
Každý uzel zde obsahuje atribut (vlastnost), který se stává kořenovou příčinou dalšího dělení směrem dolů.
Můžete odpovědět,
- Jak rozhodnout, který rys by měl být umístěn v kořenovém uzlu,
- Nejpřesnější rys, který má sloužit jako vnitřní uzly nebo listové uzly,
- Jak rozdělit strom,
- Jak změřit přesnost rozdělení stromu a mnoho dalších.
Existuje několik základních parametrů dělení, které řeší výše uvedené značné problémy. A ano, v oblasti tohoto článku se budeme zabývat entropií, Giniho indexem, informačním ziskem a jejich úlohou při provádění techniky rozhodovacích stromů.
V průběhu rozhodovacího procesu se účastní více rysů a stává se nezbytným zabývat se významem a důsledky každého rysu, a tak přiřadit příslušný rys v kořenovém uzlu a procházet štěpením uzlů směrem dolů.
Postup směrem dolů vede ke snížení úrovně nečistoty a neurčitosti a přináší lepší klasifikaci nebo elitní rozdělení v každém uzlu.
Pro řešení téhož se používají míry rozdělení, jako je entropie, informační zisk, Giniho index atd.
Definice entropie
„Co je to entropie?“ „Co je to entropie? Podle Lymana to není nic jiného než míra neuspořádanosti nebo míra čistoty. V podstatě je to měření nečistoty neboli náhodnosti v datových bodech.
Vysoký řád neuspořádanosti znamená nízkou úroveň nečistoty, dovolte mi to zjednodušit. Entropie se počítá mezi 0 a 1, i když v závislosti na počtu skupin nebo tříd přítomných v souboru dat může být větší než 1, ale znamená to stejný význam, tj. vyšší úroveň neuspořádanosti.
Pro jednoduchý výklad omezme hodnotu entropie mezi 0 a 1.
Na následujícím obrázku je ve tvaru obráceného „U“ znázorněna změna entropie v grafu, osa x představuje datové body a osa y hodnotu entropie. Entropie je nejnižší (bez neuspořádanosti) na krajních bodech (oba konce) a maximální (vysoká neuspořádanost) uprostřed grafu.

„Entropie je stupeň náhodnosti nebo neurčitosti, zase splňuje cíl datových vědců a ML modelů snížit neurčitost.“
Co je to informační zisk?
Pojmem entropie hraje důležitou roli při výpočtu informačního zisku.
Informační zisk se používá ke kvantifikaci toho, který rys poskytuje maximální informaci o klasifikaci na základě pojmu entropie, tj. kvantifikací velikosti neurčitosti, neuspořádanosti nebo nečistoty, obecně se záměrem snížit množství entropie počínaje vrcholem (kořenový uzel) směrem dolů(listové uzly).
Zisk informace se bere jako součin pravděpodobností třídy s logaritmem majícím základ 2 pravděpodobnosti této třídy, vzorec pro entropii je uveden níže:
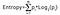
Zde „p“ označuje pravděpodobnost, která je funkcí entropie.
Giniho index v akci
Giniho index, známý také jako Giniho nečistota, vypočítává velikost pravděpodobnosti, že určitý rys bude při náhodném výběru klasifikován nesprávně. Pokud jsou všechny prvky spojeny s jedinou třídou, pak ji lze nazvat čistou.
Vnímejme kritérium Giniho indexu, podobně jako vlastnosti entropie se Giniho index pohybuje mezi hodnotami 0 a 1, kde 0 vyjadřuje čistotu klasifikace, tj. všechny prvky patří do určité třídy nebo v ní existuje pouze jedna třída. A 1 vyjadřuje náhodné rozložení prvků v různých třídách. Hodnota 0,5 Giniho indexu ukazuje rovnoměrné rozložení prvků v některých třídách.
Při návrhu rozhodovacího stromu by byly upřednostněny prvky, které mají nejmenší hodnotu Giniho indexu. Můžete se naučit další algoritmus založený na stromu(Náhodný les).
Giniho index se určí odečtením součtu kvadrátů pravděpodobností jednotlivých tříd od jedné, matematicky lze Giniho index vyjádřit takto:
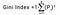
Kde Pi označuje pravděpodobnost zařazení prvku do různé třídy.
Algoritmus klasifikačního a regresního stromu (CART) využívá metodu Giniho indexu ke vzniku binárních rozdělení.
Algoritmy rozhodovacího stromu navíc využívají informační zisk k rozdělení uzlu a Giniho index nebo entropie je průchodem k vážení informačního zisku.
Giniho index vs Informační zisk
Podívejte se níže na získání rozporu mezi Giniho indexem a Informačním ziskem,
- Giniho index usnadňuje větší rozdělení, takže se snadno implementuje, zatímco Informační zisk upřednostňuje menší rozdělení, která mají malý počet s více konkrétními hodnotami.
- Metodu Giniho indexu používají algoritmy CART, na rozdíl od ní se Informační zisk používá v algoritmech ID3, C4.5. Na rozdíl od Giniho indexu se Giniho index používá v algoritmech CART.
- Giniho index pracuje s kategorickými cílovými proměnnými ve smyslu „úspěch“ nebo „neúspěch“ a provádí pouze binární rozdělení, naproti tomu Information Gain počítá rozdíl mezi entropií před a po rozdělení a udává nečistotu ve třídách prvků.
Závěr
Giniho index a Information Gain se používají pro analýzu scénáře v reálném čase a data jsou reálná, která jsou zachycena z analýzy v reálném čase. V četných definicích se také uvádí jako „nečistota dat“ nebo “ jak jsou data rozložena. Můžeme tedy vypočítat, která data se na rozhodování podílejí méně nebo více.
Dnes končím s našimi nejčtenějšími texty:
- Co je OpenAI GPT-3?
- Reliance Jio a JioMart:
- 6 hlavních odvětví umělé inteligence(AI): Marketingová strategie, SWOT analýza a fungující ekosystém.
- Top 10 Big Data technologií v roce 2020
- Jak analytika mění pohostinství
Skvělé, dostali jste se až na konec tohoto blogu! Děkujeme vám za přečtení!!!!!