
TLDR: Indexování je jen způsob seskupování dokumentů, rozdělení kolekcí do skupin pro urychlení výkonu
Přehled
Indexy zvyšují výkonnost dotazů, stejně jako se používají pro vyhledávání
Myšlenka indexování v MongoDB je podobná indexu jakékoli knihy, Zvyšují rychlost nalezení stránky. Index v MongoDB zvyšuje rychlost vyhledávání dokumentů
Jak fungují indexy
Nejdříve pochopíme, jak se deklaruje index v MongoDB
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Tady je pole „fieldName“, které bude indexováno. „Value“ může být -1 nebo 1 nebo „text“.
Definuje typ indexu, 1 nebo -1 zvyšuje výkonnost dotazu find(), zatímco „text“ se používá pro vyhledávání.
1 a -1 udávají pořadí indexu. Vzestupně = -1 & Sestupně =1
Nyní, jak indexy fungují pod pokličkou?
Představte si kolekci uživatelů, každý dokument obsahuje různé informace, jednou z nich je skóre.
Řekněme, že chceme, aby všichni uživatelé měli skóre 23.
Předpokládejme, že chceme, aby všichni uživatelé měli skóre 23.
Představte si kolekci uživatelů.
Když neexistuje žádný index, MongoDB prochází každý dokument, aby našla dotazovaný dokument, Tomu se říká skenování kolekce, MongoDB má pro to zkratku COLLSCAN (v relačních databázích se tomu říká skenování tabulky)
Jak to můžeme optimalizovat?
Pro optimalizaci můžeme vytvořit tabulku s jedním sloupcem pro skóre a druhým sloupcem pro reference, který bude obsahovat ID dokumentů s daným skóre. Nyní musíme prohledávat pouze tuto tabulku, místo abychom prohledávali celou databázi. To je mnohem rychlejší. Přesně to je index.
Indexy pomáhají MongoDB zúžit množinu dat, kterou bude muset prohledat. Tomu se říká Index Scan, MongoDB pro to má také zkratku IXNSCAN
Tady je vizuální znázornění indexu skóre a jeho mapování.
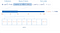
Zlepšení výkonu pomocí indexu se projeví, až když počet dokumentů překročí 100 tisíc nebo více.
Můžete si to sami porovnat tak, že porovnáte dva dotazy, jeden s indexovaným polem a druhý bez Indexu
db.<collection name>.find(query).explain()
Vrácen bude objekt
objekt.Vítězný plán.stage vám řekne typ skenování COLLSCAN nebo IXNSCAN
ale neřekne vám čas potřebný k provedení
použijte metodu explain(‚executionStat‘) před metodou dotazu jako find
.
db.<collection name>explain('executionStat').find(query)

executionTimeMillis vám řekne čas potřebný při provádění
Výhody indexu
Indexy nejsou volné, Indexy stojí místo. Indexy mohou zvýšit rychlost čtení, ale kdykoli se něco zapíše, musí se index aktualizovat, abychom to vyřešili, používáme B-strom, před vložením provedeme nějaké výpočty, takže je to rychlejší.
B-strom
Indexy nejsou tabulka skupin, koncepčně je to vlastně B-strom (binární strom) nejen MongoDB, databáze SQL také používá B-strom pro indexování
toto video nejlépe vysvětluje B-strom
.