
Es wird empfohlen, vor dem Lesen dieses Artikels zu verstehen, was ein neuronales Netz ist. Beim Aufbau eines neuronalen Netzes müssen Sie unter anderem entscheiden, welche Aktivierungsfunktion Sie in der versteckten Schicht und in der Ausgabeschicht des Netzes verwenden wollen. In diesem Artikel werden einige dieser Entscheidungen erörtert.
Elemente eines neuronalen Netzes:-
Eingabeschicht:- Diese Schicht nimmt Eingangsmerkmale entgegen. In dieser Schicht werden keine Berechnungen durchgeführt, die Knoten leiten die Informationen (Merkmale) lediglich an die verborgene Schicht weiter.
Verborgene Schicht :- Die Knoten dieser Schicht sind der Außenwelt nicht ausgesetzt, sie sind Teil der Abstraktion, die jedes neuronale Netz bietet. Die verborgene Schicht führt alle Arten von Berechnungen an den Merkmalen durch, die durch die Eingabeschicht eingegeben werden, und überträgt das Ergebnis an die Ausgabeschicht.
Ausgabeschicht:- Diese Schicht bringt die vom Netz gelernten Informationen in die Außenwelt.
Was ist eine Aktivierungsfunktion und warum sollte man sie verwenden?
Definition der Aktivierungsfunktion:- Die Aktivierungsfunktion entscheidet, ob ein Neuron aktiviert werden soll oder nicht, indem sie eine gewichtete Summe berechnet und eine weitere Vorspannung hinzufügt. Der Zweck der Aktivierungsfunktion ist es, Nichtlinearität in die Ausgabe eines Neurons einzuführen.
Erläuterung:-
Wie wir wissen, hat ein neuronales Netz Neuronen, die in Übereinstimmung mit Gewicht, Vorspannung und ihrer jeweiligen Aktivierungsfunktion arbeiten. In einem neuronalen Netz würden wir die Gewichte und Vorspannungen der Neuronen auf der Grundlage des Fehlers am Ausgang aktualisieren. Dieser Prozess wird als Back-Propagation bezeichnet. Aktivierungsfunktionen ermöglichen die Backpropagation, da die Gradienten zusammen mit dem Fehler geliefert werden, um die Gewichte und Vorspannungen zu aktualisieren.
Warum brauchen wir nichtlineare Aktivierungsfunktionen :-
Ein neuronales Netz ohne Aktivierungsfunktion ist im Grunde nur ein lineares Regressionsmodell. Die Aktivierungsfunktion führt die nichtlineare Transformation der Eingabe durch, wodurch es in der Lage ist, zu lernen und komplexere Aufgaben auszuführen.
Mathematischer Beweis :-
Angenommen, wir haben ein neuronales Netz wie dieses :-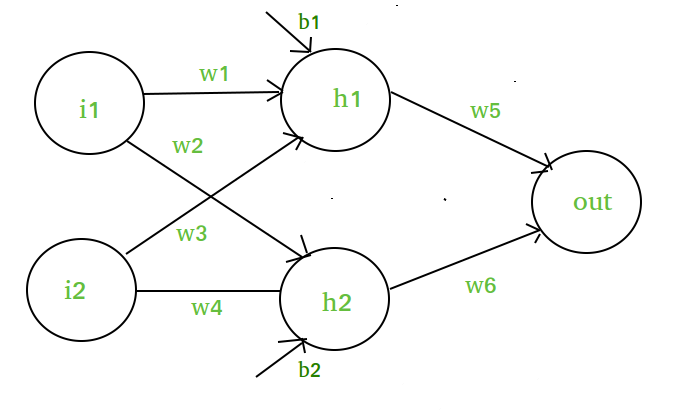
Elemente des Diagramms :-
Versteckte Schicht d.h. Schicht 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Hier ist
- z(1) die vektorisierte Ausgabe der Schicht 1
- W(1) sind die vektorisierten Gewichte, die den Neuronen
der verborgenen Schicht zugeordnet sind, d. h.d.h. w1, w2, w3 und w4- X sind die vektorisierten Eingangsmerkmale d.h. i1 und i2
- b ist der vektorisierte Bias, der den Neuronen in der versteckten
Schicht zugewiesen wird, d. h. b1 und b2- a(1) ist die vektorisierte Form einer beliebigen linearen Funktion.
(Anmerkung: Wir betrachten hier keine Aktivierungsfunktion)
Schicht 2 d. h. Ausgabeschicht:-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Berechnung auf der Ausgabeschicht:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Diese Beobachtung ergibt auch nach der Anwendung einer versteckten Schicht eine lineare Funktion, woraus wir schließen können, dass es keine Rolle spielt, wie viele versteckte Schichten wir in einem neuronalen Netz anbringen, alle Schichten werden sich gleich verhalten, da die Zusammensetzung zweier linearer Funktionen selbst eine lineare Funktion ist. Ein Neuron kann nicht lernen, wenn ihm nur eine lineare Funktion zugewiesen wird. Eine nicht-lineare Aktivierungsfunktion lässt es entsprechend der Differenz zum Fehler lernen.
Daher brauchen wir eine Aktivierungsfunktion.
VARIANTEN VON AKTIVIERUNGSFUNKTIONEN:-
1). Lineare Funktion :-
- Gleichung : Lineare Funktion hat die Gleichung ähnlich wie eine gerade Linie, d.h. y = ax
- Egal wie viele Schichten wir haben, wenn alle linear sind, ist die endgültige Aktivierungsfunktion der letzten Schicht nichts anderes als eine lineare Funktion der Eingabe der ersten Schicht.
- Bereich : -inf bis +inf
- Verwendung : Lineare Aktivierungsfunktion wird nur an einer Stelle verwendet, d.h.d. h. in der Ausgabeschicht.
- Probleme : Wenn wir die lineare Funktion differenzieren, um Nichtlinearität zu erzeugen, hängt das Ergebnis nicht mehr von der Eingabe „x“ ab und die Funktion wird konstant, es wird kein bahnbrechendes Verhalten in unseren Algorithmus eingeführt.
Beispiel : Die Berechnung des Preises eines Hauses ist ein Regressionsproblem. Der Hauspreis kann jeden großen/kleinen Wert haben, also können wir eine lineare Aktivierung auf der Ausgabeschicht anwenden. Auch in diesem Fall muss das neuronale Netz eine nicht-lineare Funktion in den versteckten Schichten haben.
2). Sigmoid-Funktion :-
- Es ist eine Funktion, die als S-förmiger Graph gezeichnet wird.
- Gleichung :
A = 1/(1 + e-x) - Art : Nichtlinear. Beachten Sie, dass die X-Werte zwischen -2 und 2 liegen, die Y-Werte sind sehr steil. Das bedeutet, dass kleine Änderungen in x auch große Änderungen im Wert von Y bewirken würden.
- Wertebereich : 0 bis 1
- Verwendung : Wird normalerweise in der Ausgabeschicht einer binären Klassifizierung verwendet, bei der das Ergebnis entweder 0 oder 1 ist, da der Wert für die Sigmoidfunktion nur zwischen 0 und 1 liegt, so dass das Ergebnis leicht als 1 vorhergesagt werden kann, wenn der Wert größer als 0,5 ist, und ansonsten 0.
3). Tanh-Funktion :- Die Aktivierung, die fast immer besser funktioniert als die Sigmoid-Funktion, ist die Tanh-Funktion, auch bekannt als tangentiale hyperbolische Funktion. Sie ist eigentlich eine mathematisch verschobene Version der Sigmoidfunktion. Beide sind ähnlich und können voneinander abgeleitet werden.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Wertebereich :- -1 bis +1
- Natur :- nicht-linear
- Verwendung :- Wird normalerweise in versteckten Schichten eines neuronalen Netzes verwendet, da seine Werte zwischen -1 und 1 liegen, so dass der Mittelwert für die versteckte Schicht 0 oder sehr nahe daran liegt, was bei der Zentrierung der Daten hilft, indem der Mittelwert nahe an 0 gebracht wird. Das macht das Lernen für die nächste Schicht viel einfacher.
- Gleichung :- A(x) = max(0,x). Es gibt eine Ausgabe x, wenn x positiv ist und 0 sonst.
- Wertebereich :- [0, inf)
- Natur :- nicht-linear, was bedeutet, dass wir leicht backpropagate die Fehler und haben mehrere Schichten von Neuronen durch die ReLU-Funktion aktiviert.
- Verwendungen :- ReLu ist weniger rechenaufwendig als tanh und sigmoid, weil es einfachere mathematische Operationen beinhaltet. Es werden jeweils nur wenige Neuronen aktiviert, was das Netz spärlich macht und es effizient und leicht berechenbar macht.
4). RELU :- Steht für Rectified linear unit. Es ist die am häufigsten verwendete Aktivierungsfunktion. Sie wird hauptsächlich in versteckten Schichten eines neuronalen Netzes implementiert.
In einfachen Worten, RELU lernt viel schneller als die Sigmoid und Tanh Funktion.
5). Softmax-Funktion :- Die Softmax-Funktion ist auch eine Art von Sigmoid-Funktion, aber sie ist praktisch, wenn wir versuchen, Klassifizierungsprobleme zu behandeln.
- Natur :- nicht-linear
- Verwendung :- Normalerweise verwendet, wenn wir versuchen, mehrere Klassen zu behandeln. Die Softmax-Funktion würde die Ausgaben für jede Klasse zwischen 0 und 1 quetschen und auch durch die Summe der Ausgaben teilen.
- Ausgabe:- Die Softmax-Funktion wird idealerweise in der Ausgabeschicht des Klassifikators verwendet, wo wir tatsächlich versuchen, die Wahrscheinlichkeiten zu erreichen, um die Klasse jeder Eingabe zu definieren.
- Wenn man wirklich nicht weiß, welche Aktivierungsfunktion man verwenden soll, kann man als Faustregel einfach RELU verwenden, da es eine allgemeine Aktivierungsfunktion ist und heutzutage in den meisten Fällen verwendet wird.
- Wenn Ihre Ausgabe für eine binäre Klassifizierung bestimmt ist, dann ist die Sigmoid-Funktion eine sehr natürliche Wahl für die Ausgabeschicht.
Auswahl der richtigen Aktivierungsfunktion
Fußnote:-
Die Aktivierungsfunktion führt die nicht-lineare Transformation der Eingabe durch, wodurch sie in der Lage ist, zu lernen und komplexere Aufgaben zu erfüllen.