

Comenzando con la Minería de Datos, un enfoque recientemente refinado de tamaño único para ser adoptado con éxito en la predicción de datos, es un método propicio utilizado para el análisis de datos para descubrir las tendencias y las conexiones en los datos que podrían arrojar una interferencia genuina.
Algunas herramientas populares operadas en la minería de datos son las redes neuronales artificiales (RNA), la regresión logística, el análisis discriminante y los árboles de decisión.
El árbol de decisión es la herramienta más notoria y poderosa que es fácil de entender y rápida de implementar para el descubrimiento de conocimiento a partir de conjuntos de datos enormes y complejos.
Introducción
El número de teóricos y practicantes están repasando regularmente las técnicas con el fin de hacer el proceso más riguroso, adecuado y rentable.
Inicialmente, los árboles de decisión se utilizan en la teoría de la decisión y la estadística a gran escala. También son herramientas convincentes en la minería de datos, la recuperación de información, la minería de textos y el reconocimiento de patrones en el aprendizaje automático.
Aquí, recomendaría la lectura de mi artículo anterior para detenerse y agudizar el conjunto de conocimientos en términos de árboles de decisión.
La esencia de los árboles de decisión prevalece en la división de los conjuntos de datos en sus secciones que emergen indirectamente un árbol de decisión (invertido) que tiene nodos raíces en la parte superior. El modelo estratificado del árbol de decisión conduce al resultado final a través del paso por los nodos de los árboles.
Aquí, cada nodo comprende un atributo (característica) que se convierte en la causa raíz de la posterior división en la dirección descendente.
¿Puede usted responder,
- Cómo decidir qué característica debe ubicarse en el nodo raíz,
- Característica más precisa para servir como nodos internos o nodos hoja,
- Cómo dividir el árbol,
- Cómo medir la precisión del árbol de división y muchos más.
Hay algunos parámetros de división fundamentales para abordar las cuestiones considerables discutidas anteriormente. Y sí, en el ámbito de este artículo, cubriremos la Entropía, el Índice de Gini, la Ganancia de Información y su papel en la ejecución de la técnica de los Árboles de Decisión.
Durante el proceso de toma de decisiones, participan múltiples características y se vuelve esencial preocuparse por la relevancia y las consecuencias de cada característica asignando así la característica apropiada en el nodo raíz y atravesando la división de nodos hacia abajo.
Marchar hacia la dirección descendente conduce a la disminución del nivel de impureza e incertidumbre y da lugar a una mejor clasificación o división de la élite en cada nodo.
Para resolver lo mismo, se utilizan medidas de división como la Entropía, la Ganancia de Información, el Índice de Gini, etc.
Definiendo la Entropía
«¿Qué es la entropía?» En palabras de Lyman, no es más que la medida del desorden, o la medida de la pureza. Básicamente, es la medida de la impureza o aleatoriedad en los puntos de datos.
Un alto orden de desorden significa un bajo nivel de impureza, déjame simplificarlo. La entropía se calcula entre 0 y 1, aunque dependiendo del número de grupos o clases presentes en el conjunto de datos podría ser mayor que 1 pero significa el mismo significado, es decir, mayor nivel de desorden.
Para una interpretación sencilla, limitemos el valor de la entropía entre 0 y 1.
En la siguiente imagen, una forma de «U» invertida representa la variación de la entropía en el gráfico, el eje x presenta los puntos de datos y el eje y muestra el valor de la entropía. La entropía es la más baja (sin desorden) en los extremos (ambos extremos) y la máxima (alto desorden) en el centro del gráfico.

«La entropía es un grado de aleatoriedad o incertidumbre, a su vez, satisface el objetivo de los Científicos de Datos y de los modelos ML de reducir la incertidumbre.»
¿Qué es la ganancia de información?
El concepto de entropía juega un papel importante en el cálculo de la ganancia de información.
La ganancia de información se aplica para cuantificar qué característica proporciona la máxima información sobre la clasificación basada en la noción de entropía, es decir cuantificando el tamaño de la incertidumbre, el desorden o la impureza, en general, con la intención de disminuir la cantidad de entropía que se inicia desde la parte superior (nodo raíz) hasta la parte inferior (nodos hojas).
La ganancia de información toma el producto de las probabilidades de la clase con un logaritmo de base 2 de esa probabilidad de clase, la fórmula de la Entropía se da a continuación:
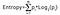
Aquí «p» denota la probabilidad que es una función de la entropía.
Índice de Gini en acción
El Índice de Gini, también conocido como impureza de Gini, calcula la cantidad de probabilidad de una característica específica que se clasifica incorrectamente cuando se selecciona al azar. Si todos los elementos están vinculados con una sola clase, entonces se puede llamar pura.
Percibamos el criterio del Índice de Gini, al igual que las propiedades de la entropía, el índice de Gini varía entre los valores 0 y 1, donde 0 expresa la pureza de la clasificación, es decir, todos los elementos pertenecen a una clase específica o sólo existe una clase en ella. Y 1 indica la distribución aleatoria de los elementos entre varias clases. El valor de 0,5 del Índice de Gini muestra una distribución equitativa de los elementos entre algunas clases.
Al diseñar el árbol de decisión, se preferirán las características que posean el menor valor del Índice de Gini. Puede aprender otro algoritmo basado en árboles (Random Forest).
El Índice de Gini se determina deduciendo la suma de los cuadrados de las probabilidades de cada clase a partir de uno, matemáticamente, el Índice de Gini se puede expresar como:
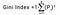
Donde Pi denota la probabilidad de que un elemento sea clasificado para una clase distinta.
El algoritmo de Árbol de Clasificación y Regresión (CART) despliega el método del Índice de Gini para originar divisiones binarias.
Además, los algoritmos de árboles de decisión explotan la Ganancia de Información para dividir un nodo y el Índice de Gini o Entropía es la vía para ponderar la Ganancia de Información.
Índice de Gini vs Ganancia de Información
Mira a continuación para ver la discrepancia entre el Índice de Gini y la Ganancia de Información,
- El Índice de Gini facilita las distribuciones más grandes tan fáciles de implementar mientras que la Ganancia de Información favorece las distribuciones menores que tienen una cuenta pequeña con múltiples valores específicos.
- El método del Índice de Gini es utilizado por los algoritmos CART, en cambio la Ganancia de Información es utilizada en los algoritmos ID3, C4.5.
- El índice de Gini opera sobre las variables objetivo categóricas en términos de «éxito» o «fracaso» y realiza sólo la división binaria, en contraposición a ello la Ganancia de Información computa la diferencia entre la entropía antes y después de la división e indica la impureza en las clases de elementos.
Conclusión
El índice de Gini y la Ganancia de Información se utilizan para el análisis del escenario en tiempo real, y los datos son reales que se capturan del análisis en tiempo real. En numerosas definiciones, también se ha mencionado como «impureza de los datos» o «cómo se distribuyen los datos». Así que podemos calcular qué datos están tomando menos o más parte en la toma de decisiones.
Hoy termino con nuestro top de lecturas:
- ¿Qué es OpenAI GPT-3?
- Reliance Jio y JioMart: Estrategia de marketing, análisis DAFO y ecosistema de trabajo.
- 6 Grandes ramas de la Inteligencia Artificial(IA).
- Las 10 principales tecnologías de Big Data en 2020
- Cómo la analítica está transformando la industria de la hostelería
¡Oh, genial, has llegado al final de este blog! Gracias por leer!!!!!