
Se recomienda entender qué es una red neuronal antes de leer este artículo. En El proceso de construcción de una red neuronal, una de las opciones que se llega a hacer es qué función de activación a utilizar en la capa oculta, así como en la capa de salida de la red. Este artículo analiza algunas de las opciones.
Elementos de una red neuronal :-
Capa de entrada :- Esta capa acepta características de entrada. Proporciona información del mundo exterior a la red, no se realiza ningún cálculo en esta capa, los nodos aquí sólo pasan la información (características) a la capa oculta.
Capa oculta :- Los nodos de esta capa no están expuestos al mundo exterior, son la parte de la abstracción proporcionada por cualquier red neuronal. La capa oculta realiza todo tipo de cálculos sobre las características introducidas a través de la capa de entrada y transfiere el resultado a la capa de salida.
Capa de salida :- Esta capa lleva la información aprendida por la red al mundo exterior.
¿Qué es una función de activación y por qué utilizarla?
Definición de la función de activación:- La función de activación decide si una neurona debe ser activada o no calculando la suma ponderada y añadiendo además un sesgo. El propósito de la función de activación es introducir la no linealidad en la salida de una neurona.
Explicación :-
Sabemos, la red neuronal tiene neuronas que trabajan en correspondencia de peso, sesgo y su respectiva función de activación. En una red neuronal, actualizaríamos los pesos y sesgos de las neuronas en función del error en la salida. Este proceso se conoce como retropropagación. Las funciones de activación hacen posible la retropropagación, ya que los gradientes se suministran junto con el error para actualizar los pesos y los sesgos.
Por qué necesitamos funciones de activación no lineales :-
Una red neuronal sin función de activación es esencialmente sólo un modelo de regresión lineal. La función de activación realiza la transformación no lineal de la entrada haciendo que sea capaz de aprender y realizar tareas más complejas.
Prueba matemática :-
Supongamos que tenemos una red neuronal como esta :-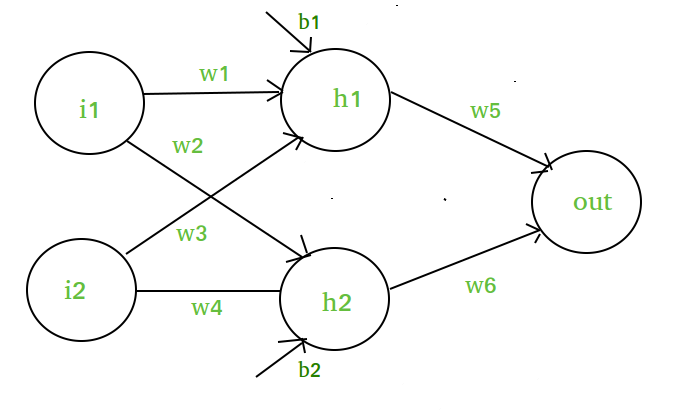
Elementos del diagrama :-
Capa oculta, es decir capa 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Aquí,
- z(1) es la salida vectorizada de la capa 1
- W(1) son los pesos vectorizados asignados a las neuronas
de la capa oculta i.e. w1, w2, w3 y w4- X son las características de entrada vectorizadas, es decir i1 e i2
- b es el sesgo vectorial asignado a las neuronas en la capa oculta
es decir, b1 y b2- a(1) es la forma vectorial de cualquier función lineal.
(Nota: No estamos considerando la función de activación aquí)
Capa 2 es decir capa de salida :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Cálculo en la capa de salida:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Esta observación resulta de nuevo en una función lineal incluso después de aplicar una capa oculta, por lo que podemos concluir que, no importa cuántas capas ocultas adjuntemos en la red neuronal, todas las capas se comportarán de la misma manera porque la composición de dos funciones lineales es una función lineal en sí misma. La neurona no puede aprender sólo con una función lineal unida a ella. Una función de activación no lineal le permitirá aprender según la diferencia con el error.
De ahí que necesitemos una función de activación.
VARIANTES DE LA FUNCIÓN DE ACTIVACIÓN :-
1). Función lineal :-
- Ecuación : La función lineal tiene la ecuación similar a la de una línea recta, es decir, y = ax
- No importa cuántas capas tengamos, si todas son de naturaleza lineal, la función de activación final de la última capa no es más que una función lineal de la entrada de la primera capa.
- Rango : -inf a +inf
- Usos : La función de activación lineal se utiliza en un solo lugar i.Si diferenciamos la función lineal para que no sea lineal, el resultado no dependerá de la entrada «x» y la función será constante, no introducirá ningún comportamiento innovador en nuestro algoritmo.
Por ejemplo: el cálculo del precio de una casa es un problema de regresión. El precio de la casa puede tener cualquier valor grande/pequeño, por lo que podemos aplicar la activación lineal en la capa de salida. Incluso en este caso la red neuronal debe tener cualquier función no lineal en las capas ocultas.
2). Función Sigmoide :-
- Es una función que se traza como gráfico en forma de ‘S’.
- Ecuación :
A = 1/(1 + e-x) - Naturaleza : No lineal. Obsérvese que los valores de X se encuentran entre -2 y 2, los valores de Y son muy pronunciados. Esto significa que pequeños cambios en x también provocan grandes cambios en el valor de Y.
- Rango de valores : 0 a 1
- Usos : Normalmente se utiliza en la capa de salida de una clasificación binaria, donde el resultado es 0 o 1, ya que el valor de la función sigmoide se encuentra entre 0 y 1 solamente, por lo que el resultado se puede predecir fácilmente para ser 1 si el valor es mayor que 0,5 y 0 en caso contrario.
3). Función Tanh :- La activación que funciona casi siempre mejor que la función sigmoidea es la función Tanh, también conocida como función hiperbólica tangente. En realidad es una versión matemáticamente desplazada de la función sigmoidea. Ambas son similares y se pueden derivar la una de la otra.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Rango de valores :- -1 a +1
- Naturaleza :- no lineal
- Usos :- Normalmente se utiliza en las capas ocultas de una red neuronal ya que sus valores se encuentran entre -1 y 1 por lo que la media de la capa oculta es 0 o muy cercana a ella, por lo que ayuda a centrar los datos acercando la media a 0. Esto hace que el aprendizaje de la siguiente capa sea mucho más fácil.) RELU :- Significa unidad lineal rectificada. Es la función de activación más utilizada. Se implementa principalmente en las capas ocultas de la red neuronal.
- Ecuación :- A(x) = max(0,x). Da una salida x si x es positiva y 0 en caso contrario.
- Rango de valores :- [0, inf)
- Naturaleza :- no lineal, lo que significa que podemos retropropagar fácilmente los errores y tener múltiples capas de neuronas siendo activadas por la función ReLU.
- Usos :- ReLu es menos caro computacionalmente que tanh y sigmoide porque implica operaciones matemáticas más simples. A la vez, sólo se activan unas pocas neuronas, lo que hace que la red sea poco densa y que sea eficiente y fácil de calcular.
En palabras sencillas, RELU aprende mucho más rápido que la función sigmoide y Tanh.
5). Función Softmax :- La función softmax es también un tipo de función sigmoide, pero es útil cuando estamos tratando de manejar los problemas de clasificación.
- Naturaleza :- no lineal
- Usos :- Por lo general se utiliza cuando se trata de manejar múltiples clases. La función softmax exprimiría las salidas para cada clase entre 0 y 1 y también dividiría por la suma de las salidas.
- Salida:- La función softmax se utiliza idealmente en la capa de salida del clasificador donde realmente estamos tratando de alcanzar las probabilidades para definir la clase de cada entrada.
- La regla básica es que si realmente no sabes qué función de activación utilizar, entonces simplemente utiliza RELU ya que es una función de activación general y se utiliza en la mayoría de los casos hoy en día.
- Si su salida es para la clasificación binaria, entonces, la función sigmoide es una opción muy natural para la capa de salida.
Cómo elegir la función de activación adecuada
Nota de pie :-
La función de activación hace la transformación no lineal a la entrada haciendo que sea capaz de aprender y realizar tareas más complejas.