

Az adatbányászattal kezdve, egy újonnan finomított egyméretű megközelítés, amelyet sikeresen alkalmaznak az adatok előrejelzésében, ez egy kedvező módszer, amelyet adatelemzésre használnak, hogy felfedezzék az adatokban a trendeket és a kapcsolatokat, amelyek valódi beavatkozást vethetnek.
Az adatbányászatban működtetett néhány népszerű eszköz a mesterséges neurális hálózatok(ANN), a logisztikai regresszió, a diszkrimináns elemzés és a döntési fák.
A döntési fa a leghíresebb és leghatékonyabb eszköz, amely könnyen érthető és gyorsan alkalmazható a hatalmas és összetett adathalmazokból történő tudásfeltárásra.
Bevezetés
Az elméleti és gyakorlati szakemberek száma rendszeresen újrapolírozza a technikákat, hogy a folyamatot szigorúbbá, megfelelőbbé és költséghatékonyabbá tegye.
A döntési fákat kezdetben a döntéselméletben és a statisztikában használják széles körben. Ezek is meggyőző eszközök az adatbányászatban, az információkeresésben, a szövegbányászatban és a mintafelismerésben a gépi tanulásban.
Itt azt ajánlom, hogy olvassa el az előző cikkemet, hogy elmerüljön és élesítse a tudáskészletét a döntési fák szempontjából.
A döntési fák lényege az adathalmazok felosztásában érvényesül, amelyek közvetve kialakuló döntési fa (inverz), amelynek gyökerei csomópontok a tetején. A döntési fa rétegzett modellje a fák csomópontjainak áthaladásán keresztül vezet a végeredményhez.
Itt minden egyes csomópont egy attribútumot (jellemzőt) tartalmaz, amely a lefelé irányuló további felosztás gyökerévé válik.
Válaszoljon,
- Hogyan döntsük el, hogy melyik jellemző legyen a gyökércsomópontban,
- A legpontosabb jellemző, amely belső csomópontként vagy levélcsomópontként szolgál,
- Hogyan osszuk fel a fát,
- Hogyan mérjük a felosztási fa pontosságát és még sok más.
A fent tárgyalt jelentős problémák kezelésére van néhány alapvető hasítási paraméter. És igen, e cikk birodalmában lefedjük az entrópiát, a Gini-indexet, az információnyereséget és szerepüket a döntési fák technikájának végrehajtásában.
A döntéshozatal folyamata során több jellemző vesz részt, és alapvető fontosságúvá válik az egyes jellemzők relevanciájának és következményeinek érintettsége, így a megfelelő jellemzőt a gyökércsomóponthoz rendeljük, és a csomópontok felosztását lefelé haladva haladunk.
A lefelé haladás a szennyeződés és a bizonytalanság szintjének csökkenéséhez vezet, és jobb osztályozást vagy elit felosztást eredményez az egyes csomópontokban.
Ezek megoldására olyan felosztási mértékeket használnak, mint az entrópia, az információnyereség, a Gini-index stb.
Az entrópia meghatározása
“Mi az entrópia?”. Lyman szavaival élve, nem más, mint a rendezetlenség, vagy a tisztaság mértéke. Alapvetően az adatpontokban lévő tisztátalanság vagy véletlenszerűség mérése.”
A nagy rendezetlenség alacsony tisztátalansági szintet jelent, hadd egyszerűsítsem le. Az entrópia számítása 0 és 1 között történik, bár az adathalmazban jelen lévő csoportok vagy osztályok számától függően lehet 1-nél nagyobb, de ugyanazt a jelentést, azaz magasabb rendezetlenségi szintet jelent.
Az egyszerű értelmezés érdekében korlátozzuk az entrópia értékét 0 és 1 közé.
Az alábbi képen egy fordított “U” alakú grafikonon az entrópia változását ábrázoljuk, az x tengely az adatpontokat, az y tengely pedig az entrópia értékét mutatja. Az entrópia a szélsőértékeknél (mindkét végén) a legalacsonyabb (nincs rendezetlenség), a grafikon közepén pedig a maximális (nagy rendezetlenség).

“Az entrópia a véletlenszerűség vagy bizonytalanság egy foka, viszont kielégíti az adattudósok és ML modellek célját a bizonytalanság csökkentésére.”
Mi az információnyereség?
Az entrópia fogalma fontos szerepet játszik az információnyereség kiszámításában.
Az információnyereséget annak számszerűsítésére alkalmazzák, hogy az entrópia fogalma alapján melyik jellemző nyújt maximális információt az osztályozásról, ill. a bizonytalanság, a rendezetlenség vagy a tisztázatlanság nagyságának számszerűsítésével, általában azzal a szándékkal, hogy a felülről (gyökércsomópont) az alulról (levélcsomópontok) kiinduló entrópia mennyisége csökkenjen.
Az információnyereség az osztály valószínűségeinek szorzatát veszi az adott osztály valószínűségének 2-es bázissal rendelkező loggal, az entrópia képlete az alábbi:
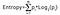
Itt a “p” a valószínűséget jelöli, amely az entrópia függvénye.
Gini-index működésben
A Gini-index, más néven Gini-tisztaság, kiszámítja, hogy egy adott jellemző mekkora valószínűséggel minősül helytelenül, ha véletlenszerűen választjuk ki. Ha minden elem egyetlen osztályhoz kapcsolódik, akkor azt tisztának nevezhetjük.
Észrevesszük a Gini-index kritériumát, az entrópia tulajdonságaihoz hasonlóan a Gini-index is 0 és 1 értékek között változik, ahol a 0 az osztályozás tisztaságát fejezi ki, azaz minden elem egy adott osztályhoz tartozik, vagy csak egy osztály létezik benne. Az 1 pedig az elemek véletlenszerű eloszlását jelzi a különböző osztályok között. A Gini-index 0,5-ös értéke az elemek egyes osztályok közötti egyenlő eloszlását mutatja.
A döntési fa tervezése során a Gini-index legkisebb értékével rendelkező jellemzőket részesítenénk előnyben. Megtanulhat egy másik fa alapú algoritmust(Random Forest).
A Gini-indexet úgy határozzuk meg, hogy az egyes osztályok valószínűségeinek négyzetének összegét levonjuk egyből, matematikailag a Gini-index a következőképpen fejezhető ki:
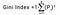
Ahol Pi azt a valószínűséget jelöli, hogy egy elem egy adott osztályba sorolható.
Az osztályozási és regressziós fa (CART) algoritmus a Gini-index módszerét alkalmazza a bináris felosztások keletkezéséhez.
A döntési fa algoritmusok emellett kihasználják az információnyereséget egy csomópont felosztásához, a Gini-index vagy entrópia pedig az információnyereség mérlegelésének átjárója.
Gini Index vs Information Gain
Nézze meg az alábbiakban a Gini Index és az Information Gain közötti eltérés megszerzését,
- A Gini Index megkönnyíti a nagyobb eloszlásokat, így könnyen megvalósítható, míg az Information Gain előnyben részesíti a kisebb eloszlásokat, amelyek kis számmal rendelkeznek több konkrét értékkel.
- A Gini Index módszerét a CART algoritmusok használják, ezzel szemben az Information Gain-t az ID3, C4.5 algoritmusok használják.
- A Gini-index a kategorikus célváltozókon a “siker” vagy a “kudarc” szempontjából működik, és csak bináris felosztást végez, ezzel szemben az Information Gain a felosztás előtti és utáni entrópia különbségét számítja ki, és jelzi az elemek osztályainak tisztázatlanságát.
Következtetés
A Gini-indexet és az Information Gaint a valós idejű forgatókönyv elemzéséhez használják, és az adatok valósak, amelyeket a valós idejű elemzésből rögzítenek. Számos definícióban az “adatok tisztátalanságaként” vagy ” az adatok eloszlásának módjaként is említik. Így kiszámíthatjuk, hogy mely adatok vesznek kevesebb vagy több szerepet a döntéshozatalban.
Ma a mai napon a top olvasmányainkkal végzek:
- Mi az OpenAI GPT-3?
- Reliance Jio és a JioMart: Marketing stratégia, SWOT elemzés és működő ökoszisztéma.
- 6 Major Branches of Artificial Intelligence(AI).
- Top 10 Big Data technológia 2020-ban
- Hogyan alakítja át az analitika a vendéglátóipart
Oh remek, eljutottál a blog végére! Köszönjük, hogy elolvasta!!!!!