
TLDR: Az indexelés csak egy módja a dokumentumok csoportosításának, a gyűjtemények csoportokra osztása a teljesítmény felgyorsítása érdekében
Áttekintés
Az indexek növelik a lekérdezések teljesítményét, valamint a keresésekhez használják
Az indexelés ötlete a MongoDB-ben hasonló bármely könyv indexéhez, Ezek növelik az oldal megtalálásának sebességét. Az index a MongoDB-ben növeli a dokumentumok megtalálásának sebességét
Hogyan működnek az indexek?
Először is, értsük meg, hogyan deklaráljuk az indexet a MongoDB-ben
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Itt a mező a “fieldName”, amelyet indexelni fogunk. “Value” lehet -1 vagy 1 vagy “text”.
Ez határozza meg az index típusát, 1 vagy -1 növeli a find() lekérdezés teljesítményét, míg a “text” a keresésre szolgál.
1 és -1 adja meg az index sorrendjét. Ascending = -1 & Descending =1
Most, hogyan működnek az indexek a motorháztető alatt?
Képzeljünk el egy felhasználói gyűjteményt, minden dokumentum különböző információkat tartalmaz, amelyek közül az egyik a pontszám.
Tegyük fel, hogy minden felhasználónak 23 pontot szeretnénk.
Ha nincs index, a MongoDB végigmegy minden egyes dokumentumon, hogy megtalálja a lekérdezett dokumentumot, Ezt hívják Collection scan-nek, a MongoDB-nek van erre egy rövidítése COLLSCAN (ezt hívják Table scan-nek a relációs adatbázisokban)
Hogyan tudjuk ezt optimalizálni?
Az optimalizáláshoz létrehozhatunk egy táblázatot, amelynek egyik oszlopa a pontszám, a másik oszlop pedig a hivatkozások, amely az adott pontszámmal rendelkező dokumentumok azonosítóit tartalmazza. Most már csak ezt a táblát kell beolvasnunk ahelyett, hogy az egész adatbázist beolvasnánk. Ez sokkal gyorsabb. Pontosan ez az, ami egy index.
Az indexek segítenek a MongoDB-nek leszűkíteni az adathalmazt, amit be kell vizsgálnia. Ezt hívják Index Scan-nek, a MongoDB-nek erre is van egy rövidítése IXNSCAN
Itt egy vizuális ábrázolása egy pontszám Indexnek és annak leképezésének.
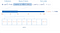
A teljesítményjavulás az Index által csak akkor látható, ha a dokumentumok száma átlépi a 100K vagy annál nagyobb számot.
Magad is összehasonlíthatod, ha két lekérdezést összehasonlítasz, egyet indexelt mezővel és egyet index nélkül
db.<collection name>.find(query).explain()
Egy objektumot fogsz visszakapni
.winingPlan.stage megmondja a letapogatás típusát COLLSCAN vagy IXNSCAN
de nem fogja megmondani a végrehajtáshoz szükséges időt
használja az explain(‘executionStat’) módszert a lekérdezési módszer előtt, mint például a find
.
db.<collection name>explain('executionStat').find(query)

executionTimeMillis megmondja a végrehajtás során eltelt időt
Az index hátrányai
Az indexek nem szabadok, Az indexek tárhelyet vesznek igénybe. Az indexek növelhetik az olvasási sebességet, de amikor valamit írunk, az indexet frissíteni kell, hogy ezt megoldjuk B- fát használunk, néhány számítást végzünk a beszúrás előtt, így gyorsabb lesz.
B-fa
Az indexek nem egy csoportokból álló táblázat, koncepcionálisan valójában egy B-fa (Binary Tree) nem csak a MongoDB, az SQL adatbázis is B-fát használ indexelésre
ez a videó magyarázza el legjobban a B-fát