
A cikk elolvasása előtt ajánlott megérteni, mi is az a neurális hálózat. A neurális hálózat építése során az egyik döntés, amit meg kell hoznod, az az, hogy milyen aktiválási függvényt használj a rejtett rétegben, valamint a hálózat kimeneti rétegében. Ez a cikk néhány választási lehetőséget tárgyal.
A neurális hálózat elemei :-
Bemeneti réteg :- Ez a réteg fogadja a bemeneti jellemzőket. A külvilágból származó információt szolgáltat a hálózatnak, ezen a rétegen nem történik számítás, az itteni csomópontok csak továbbítják az információt (jellemzőket) a rejtett rétegnek.
Rejtett réteg :- Ennek a rétegnek a csomópontjai nincsenek kitéve a külvilágnak, ők az absztrakció részét képezik, amelyet minden neurális hálózat biztosít. A rejtett réteg mindenféle számítást elvégez a bemeneti rétegen keresztül bevitt jellemzőkkel, és az eredményt átadja a kimeneti rétegnek.
Kimeneti réteg :- Ez a réteg a hálózat által megtanult információkat juttatja el a külvilágba.
Mi az aktiváló függvény és miért használjuk?
Az aktiváló függvény definíciója:- Az aktiváló függvény a súlyozott összeg kiszámításával és a hozzá tartozó előfeszítéssel dönt arról, hogy egy neuront aktiválni kell-e vagy sem. Az aktivációs függvény célja, hogy nemlinearitást vezessen be a neuron kimenetébe.
Magyarázat :-
Tudjuk, hogy a neurális hálózat neuronjai a súly, az előfeszítés és a hozzájuk tartozó aktivációs függvény megfelelésében működnek. Egy neurális hálózatban a neuronok súlyait és torzításait a kimeneti hiba alapján frissítenénk. Ezt a folyamatot back-propagációnak nevezik. Az aktivációs függvények teszik lehetővé a visszaterjedést, mivel a gradienseket a hibával együtt szolgáltatják a súlyok és az előfeszítések frissítéséhez.
Miért van szükségünk nemlineáris aktivációs függvényekre :-
A neurális hálózat aktivációs függvény nélkül lényegében csak egy lineáris regressziós modell. Az aktiváló függvény végzi a nemlineáris transzformációt a bemenethez, ami képessé teszi a tanulásra és összetettebb feladatok elvégzésére.
Matematikai bizonyítás :-
Tegyük fel, hogy van egy ilyen neurális hálózatunk :-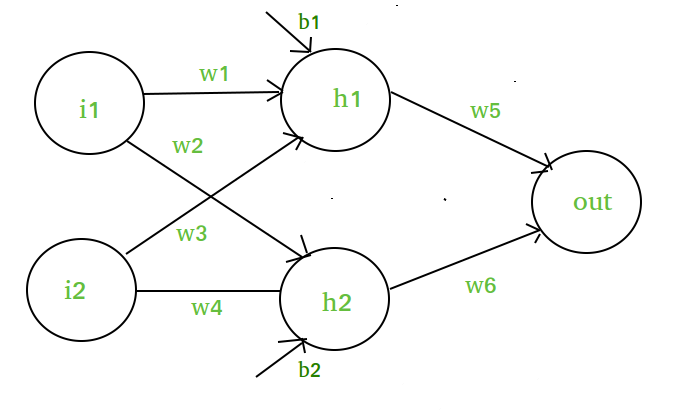
A diagram elemei :-
A rejtett réteg ill. 1. réteg :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Itt
- z(1) az 1. réteg vektorizált kimenete
- W(1) az i rejtett réteg neuronjaihoz
rendelt vektorizált súlyok.w1, w2, w3 és w4- X a vektorizált bemeneti jellemzők, azaz. i1 és i2
- b a rejtett
réteg neuronjaihoz rendelt vektorizált előfeszítés, azaz b1 és b2- a(1) bármely lineáris függvény vektorizált formája.
(Megjegyzés: Itt nem veszünk figyelembe aktiválási függvényt)
2. réteg, azaz. kimeneti réteg :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Kiszámítás a kimeneti rétegben:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Ez a megfigyelés egy rejtett réteg alkalmazása után is ismét egy lineáris függvényt eredményez, ebből arra következtethetünk, hogy, nem számít, hány rejtett réteget csatolunk a neurális hálóhoz, minden réteg ugyanúgy fog viselkedni, mert két lineáris függvény összetétele maga is egy lineáris függvény. A neuron nem tud tanulni úgy, hogy csak egy lineáris függvényt csatolunk hozzá. Egy nem lineáris aktiválási függvény lehetővé teszi, hogy a hibával szembeni különbségnek megfelelően tanuljon.
Ezért van szükségünk aktiválási függvényre.
Az aktiválási függvény változatai :-
1). Lineáris függvény :-
- Egyenlet : A lineáris függvény egyenlete hasonló, mint egy egyenesé, azaz y = ax
- Nem számít, hány rétegünk van, ha mindegyik lineáris jellegű, az utolsó réteg végső aktiválási függvénye nem más, mint az első réteg bemenetének lineáris függvénye.
- Tartomány : -inf-től +inf-ig
- Felhasználás : A lineáris aktiválási függvényt csak egy helyen használjuk i.azaz a kimeneti rétegben.
- Problémák : Ha a lineáris függvényt differenciáljuk, hogy nemlinearitást hozzunk, az eredmény már nem függ az “x” bemenettől és a függvény állandó lesz, ez nem vezet be semmilyen úttörő viselkedést az algoritmusunkba.
Példa : Egy ház árának kiszámítása regressziós probléma. A ház ára bármilyen nagy/kicsi érték lehet, ezért a kimeneti rétegben lineáris aktiválást alkalmazhatunk. Ebben az esetben is a neurális hálónak bármilyen nemlineáris függvényt kell alkalmaznia a rejtett rétegekben.
2). Szigmoid függvény :-
- Ez egy olyan függvény, amelyet “S” alakú grafikonként ábrázolunk.
- Egyenlet :
A = 1/(1 + e-x) - Természet : Nem lineáris. Vegyük észre, hogy az X értékek -2 és 2 között vannak, az Y értékek nagyon meredekek. Ez azt jelenti, hogy az x kis változásai nagy változásokat eredményeznek az Y értékében is.
- Értéktartomány : 0 és 1 között
- Felhasználás : Általában a bináris osztályozás kimeneti rétegében használják, ahol az eredmény vagy 0 vagy 1, mivel a szigmoid függvény értéke csak 0 és 1 között van, így az eredmény könnyen megjósolható, hogy 1 lesz, ha az érték nagyobb, mint 0,5, és 0 egyébként.
3). Tanh függvény :- Az aktiválás, amely szinte mindig jobban működik, mint a szigmoid függvény, a Tanh függvény, amelyet Tangens hiperbolikus függvényként is ismer. Ez valójában a szigmoid függvény matematikailag eltolt változata. Mindkettő hasonló és levezethető egymásból.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Értéktartomány :- -1 és +1 között
- Természet :- nem lineáris
- Felhasználás :- Általában a neurális hálózat rejtett rétegeiben használják, mivel értékei -1 és 1 között vannak, így a rejtett réteg átlaga 0 vagy nagyon közel van hozzá, ezért segít az adatok központosításában azáltal, hogy az átlagot 0 közelébe hozza. Ez megkönnyíti a következő réteg tanulását.
- Egyenlet :- A(x) = max(0,x). Akkor ad x kimenetet, ha x pozitív, egyébként 0.
- Értéktartomány :- [0, inf)
- Jelleg :- nem lineáris, ami azt jelenti, hogy a hibákat könnyen visszavezethetjük, és több neuronréteget aktiválhatunk a ReLU függvénnyel.
- Felhasználás :- A ReLu kevésbé számításigényes, mint a tanh és a sigmoid, mert egyszerűbb matematikai műveleteket tartalmaz. Egyszerre csak néhány neuron aktiválódik, ami a hálózatot ritkává teszi, így hatékony és könnyű számítást tesz lehetővé.
4). RELU :- Jelenti a korrigált lineáris egységet. Ez a legszélesebb körben használt aktiválási függvény. Főleg a neurális hálózat rejtett rétegeiben alkalmazzák.
Egyszerű szavakkal, a RELU sokkal gyorsabban tanul, mint a sigmoid és a Tanh függvény.
5). Softmax függvény :- A softmax függvény szintén a sigmoid függvény egy fajtája, de praktikus, amikor osztályozási problémákat próbálunk kezelni.
- Természet :- nem lineáris
- Felhasználás :- Általában akkor használjuk, amikor több osztályt próbálunk kezelni. A softmax függvény az egyes osztályok kimeneteit 0 és 1 közé szorítaná, és a kimenetek összegével is osztana.
- Kimenet:- A softmax függvényt ideálisan az osztályozó kimeneti rétegében használjuk, ahol ténylegesen megpróbáljuk elérni a valószínűségeket, hogy meghatározzuk az egyes bemenetek osztályát.
- Az alapszabály az, hogy ha tényleg nem tudja, hogy milyen aktiválási függvényt használjon, akkor egyszerűen használja a RELU-t, mivel ez egy általános aktiválási függvény, és manapság a legtöbb esetben használják.
- Ha a kimenete bináris osztályozásra szolgál, akkor a sigmoid függvény nagyon természetes választás a kimeneti réteghez.
A MEGFELELŐ AKTIVÁLÁSI FUNKCIÓ VÁLASZTÁSA
Lábjegyzet :-
Az aktiválási függvény nemlineáris transzformációt végez a bemenettel, így képes tanulni és összetettebb feladatokat végrehajtani.