
Przed przeczytaniem tego artykułu zalecane jest zrozumienie, czym jest sieć neuronowa. W procesie budowania sieci neuronowej, jednym z wyborów, które musisz podjąć jest to, jaką funkcję aktywacji użyć w warstwie ukrytej, jak również w warstwie wyjściowej sieci. Ten artykuł omawia niektóre z tych wyborów.
Elementy sieci neuronowej :-
Warstwa wejściowa :- Ta warstwa akceptuje cechy wejściowe. Dostarcza ona informacji ze świata zewnętrznego do sieci, żadne obliczenia nie są wykonywane w tej warstwie, węzły tutaj po prostu przekazują informacje (cechy) do warstwy ukrytej.
Warstwa ukryta :- Węzły tej warstwy nie są wystawione na działanie świata zewnętrznego, są częścią abstrakcji zapewnianej przez każdą sieć neuronową. Warstwa ukryta wykonuje wszelkiego rodzaju obliczenia na cechach wprowadzonych przez warstwę wejściową i przekazuje wynik do warstwy wyjściowej.
Warstwa wyjściowa :- Ta warstwa przenosi informacje wyuczone przez sieć do świata zewnętrznego.
Co to jest funkcja aktywacji i dlaczego należy jej używać?
Definicja funkcji aktywacji:- Funkcja aktywacji decyduje, czy neuron powinien być aktywowany czy nie poprzez obliczenie sumy ważonej i dodanie do niej współczynnika błędu. Celem funkcji aktywacji jest wprowadzenie nieliniowości do wyjścia neuronu.
Wyjaśnienie :-
Wiemy, że sieć neuronowa ma neurony, które działają w zależności od wagi, skosu i ich odpowiedniej funkcji aktywacji. W sieci neuronowej, będziemy aktualizować wagi i bias neuronów na podstawie błędu na wyjściu. Proces ten znany jest jako wsteczna propagacja. Funkcje aktywacji sprawiają, że wsteczna propagacja jest możliwa, ponieważ gradienty są dostarczane wraz z błędem, aby zaktualizować wagi i uprzedzenia.
Dlaczego potrzebujemy nieliniowych funkcji aktywacji :-
Sieć neuronowa bez funkcji aktywacji jest w zasadzie tylko liniowym modelem regresji. Funkcja aktywacji dokonuje nieliniowej transformacji danych wejściowych, czyniąc ją zdolną do uczenia się i wykonywania bardziej złożonych zadań.
Dowód matematyczny :-
Załóżmy, że mamy sieć neuronową taką jak ta :-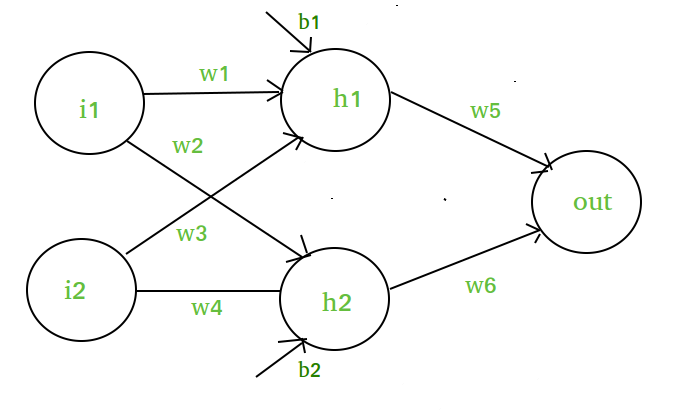
Elementy diagramu :-
Warstwa ukryta tj. warstwa 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Tutaj,
- z(1) to zwektoryzowane wyjście warstwy 1
- W(1) to zwektoryzowane wagi przypisane neuronom
warstwy ukrytej i.e. w1, w2, w3 oraz w4- X to zwektoryzowane cechy wejściowe tj. i1 i i2
- b jest zwektoryzowanym biasem przypisanym neuronom w ukrytej
warstwie tj. b1 i b2- a(1) jest zwektoryzowaną postacią dowolnej funkcji liniowej.
(Uwaga: Nie rozważamy tutaj funkcji aktywacji)
Warstwa 2 tj. warstwa wyjściowa :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Obliczenia w warstwie wyjściowej:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
W wyniku tej obserwacji otrzymujemy ponownie funkcję liniową nawet po zastosowaniu warstwy ukrytej, stąd możemy wnioskować, że nie ma znaczenia ile warstw ukrytych dołączymy w sieci neuronowej, wszystkie warstwy będą zachowywać się tak samo, ponieważ kompozycja dwóch funkcji liniowych jest sama w sobie funkcją liniową. Neuron nie może się uczyć mając tylko liniową funkcję dołączoną do niego. Nieliniowa funkcja aktywacji pozwoli mu uczyć się jak na różnicę w.r.t błąd.
Stąd potrzebujemy funkcji aktywacji.
WARIANTY FUNKCJI AKTYWACJI :-
1). Funkcja liniowa :-
- Równanie : Funkcja liniowa ma równanie podobne do równania linii prostej tj. y = ax
- Nieważne ile mamy warstw, jeśli wszystkie są liniowe, ostateczna funkcja aktywacji ostatniej warstwy jest niczym innym jak tylko liniową funkcją wejścia pierwszej warstwy.
- Zakres : -inf do +inf
- Zastosowanie : Liniowa funkcja aktywacji jest używana tylko w jednym miejscu tj.e. output layer.
- Issues : If we will differentiate linear function to bring non-linearity, result will no more depend on input „x” and function will become constant, it won’t introduce any ground-breaking behavior to our algorithm.
For example : Calculation of price of a house is a regression problem. Cena domu może mieć dowolnie dużą/małą wartość, więc możemy zastosować aktywację liniową w warstwie wyjściowej. Nawet w tym przypadku sieć neuronowa musi mieć dowolną nieliniową funkcję w warstwach ukrytych.
2). Funkcja sigmoidalna :-
- Jest to funkcja, która jest wykreślana jako wykres w kształcie litery 'S’.
- Równanie :
A = 1/(1 + e-x) - Charakter : Nieliniowy. Zauważ, że wartości X leżą w przedziale od -2 do 2, wartości Y są bardzo strome. Oznacza to, że małe zmiany w x przyniesie również duże zmiany w wartości Y.
- Zakres wartości : 0 do 1
- Zastosowanie : Zazwyczaj używane w warstwie wyjściowej klasyfikacji binarnej, gdzie wynik jest albo 0 lub 1, jak wartość dla funkcji sigmoid leży między 0 i 1 tylko tak, wynik można przewidzieć łatwo być 1, jeśli wartość jest większa niż 0,5 i 0 w przeciwnym razie.
3). Funkcja Tanh :- Aktywacja, która działa prawie zawsze lepiej niż funkcja sigmoidalna to funkcja Tanh znana również jako funkcja Tangent Hyperbolic. Jest to właściwie matematycznie przesunięta wersja funkcji sigmoidalnej. Oba są podobne i mogą być wyprowadzone z siebie.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Zakres wartości :- -1 do +1
- Nature :- nieliniowe
- Uses :- Zazwyczaj używane w ukrytych warstwach sieci neuronowej jak it’s wartości leży między -1 do 1 stąd średnia dla ukrytej warstwy wychodzi być 0 lub bardzo blisko niego, stąd pomaga w centrowaniu danych przez doprowadzenie średniej blisko 0. To sprawia, że nauka dla następnej warstwy jest dużo łatwiejsza.
- Równanie :- A(x) = max(0,x). Daje wyjście x jeśli x jest dodatnie i 0 w przeciwnym wypadku.
- Zakres wartości :- [0, inf)
- Charakter :- nieliniowy, co oznacza, że możemy łatwo wstecznie propagować błędy i mieć wiele warstw neuronów aktywowanych przez funkcję ReLU.
- Zastosowania :- ReLu jest mniej kosztowne obliczeniowo niż tanh i sigmoid, ponieważ obejmuje prostsze operacje matematyczne. W danym momencie aktywowanych jest tylko kilka neuronów, co sprawia, że sieć jest rzadka, co czyni ją wydajną i łatwą do obliczenia.
4). RELU :- Skrót od Rectified linear unit. Jest to najczęściej używana funkcja aktywacji. Głównie implementowana w ukrytych warstwach sieci neuronowej.
W prostych słowach, RELU uczy się znacznie szybciej niż funkcja sigmoid i Tanh.
5). Funkcja softmax :- Funkcja softmax jest również rodzajem funkcji sigmoidalnej, ale jest przydatna, gdy próbujemy radzić sobie z problemami klasyfikacji.
- Natura :- nieliniowa
- Zastosowanie :- Zwykle używana, gdy próbujemy radzić sobie z wieloma klasami. Funkcja softmax wycisnęłaby wyjścia dla każdej klasy pomiędzy 0 a 1, a także podzieliłaby przez sumę wyjść.
- Wyjście:- Funkcja softmax jest idealnie używana w warstwie wyjściowej klasyfikatora, gdzie faktycznie próbujemy osiągnąć prawdopodobieństwa, aby określić klasę każdego wejścia.
- Podstawową zasadą jest to, że jeśli naprawdę nie wiesz, jakiej funkcji aktywacji użyć, to po prostu użyj RELU, ponieważ jest to ogólna funkcja aktywacji i jest używana w większości przypadków w dzisiejszych czasach.
- Jeśli twoje wyjście jest dla klasyfikacji binarnej wtedy, funkcja sigmoid jest bardzo naturalnym wyborem dla warstwy wyjściowej.
WYBÓR PRAWIDŁOWEJ FUNKCJI AKTYWACJI
Uwaga :-
Funkcja aktywacji robi nieliniową transformację do wejścia czyniąc go zdolnym do uczenia się i wykonywania bardziej złożonych zadań.
.