

Zaczynając od eksploracji danych, nowo udoskonalonego podejścia typu one-size-fits, które ma być z powodzeniem przyjęte w przewidywaniu danych, jest to korzystna metoda wykorzystywana do analizy danych w celu odkrycia trendów i połączeń w danych, które mogą rzucać prawdziwe zakłócenia.
Kilka popularnych narzędzi wykorzystywanych w Data mining to sztuczne sieci neuronowe (ANN), regresja logistyczna, analiza dyskryminacyjna i drzewa decyzyjne.
Drzewo decyzyjne jest najbardziej znanym i potężnym narzędziem, które jest łatwe do zrozumienia i szybkie do wdrożenia w celu odkrywania wiedzy z ogromnych i złożonych zbiorów danych.
Wprowadzenie
Liczba teoretyków i praktyków są regularnie re-polishing technik w celu uczynienia procesu bardziej rygorystyczne, odpowiednie i opłacalne.
Początkowo, drzewa decyzyjne są wykorzystywane w teorii decyzji i statystyki na dużą skalę. Są to również istotne narzędzia w eksploracji danych, wyszukiwania informacji, eksploracji tekstu i rozpoznawania wzorców w machine learning.
Tutaj, polecam przeczytać mój poprzedni artykuł do mieszkania i wyostrzyć swoją pulę wiedzy w zakresie drzew decyzyjnych.
Istota drzew decyzyjnych przeważa w podziale zbiorów danych do jego sekcji, które pośrednio wyłaniając drzewo decyzyjne (odwrócony) o korzeniach węzłów na górze. Warstwowy model drzewa decyzyjnego prowadzi do wyniku końcowego poprzez przejście przez węzły drzewa.
Tutaj każdy węzeł zawiera atrybut (cechę), która staje się przyczyną dalszego podziału w kierunku w dół.
Czy możesz odpowiedzieć,
- Jak zdecydować, która cecha powinna znajdować się w węźle głównym,
- Najdokładniejsza cecha służąca jako węzły wewnętrzne lub węzły liści,
- Jak podzielić drzewo,
- Jak zmierzyć dokładność podziału drzewa i wiele innych.
Istnieją pewne podstawowe parametry podziału, aby rozwiązać znaczące problemy omówione powyżej. I tak, w sferze tego artykułu, będziemy pokrywać Entropia, Indeks Giniego, Zysk Informacji i ich rola w realizacji techniki Drzewa Decyzyjne.
Podczas procesu podejmowania decyzji, wiele cech uczestniczyć i staje się istotne, aby dotyczyć znaczenia i konsekwencje każdej cechy w ten sposób przypisując odpowiednią cechę w węźle głównym i przemierzając podział węzłów w dół.
Ruszanie w kierunku w dół prowadzi do zmniejszenia poziomu nieczystości i niepewności i plonów w lepszej klasyfikacji lub elitarnego podziału w każdym węźle.
Do rozwiązania tego samego, środki podziału są używane jak Entropia, Information Gain, Gini Index, etc.
Definiowanie Entropii
„Co to jest entropia?”. W słowach Lymana, to nic innego jak miara nieporządku, lub miara czystości. Zasadniczo jest to pomiar nieczystości lub losowości w punktach danych.
Wysoki rząd nieuporządkowania oznacza niski poziom nieczystości, pozwól mi to uprościć. Entropia jest obliczana między 0 a 1, chociaż w zależności od liczby grup lub klas obecnych w zbiorze danych może być większa niż 1, ale oznacza to samo znaczenie, tj. wyższy poziom nieuporządkowania.
Dla prostej interpretacji, niech nam ograniczyć wartość entropii między 0 i 1.
W poniższym obrazie, odwrócony kształt „U” przedstawia zmiany entropii na wykresie, oś x przedstawia punkty danych i oś y pokazuje wartość entropii. Entropia jest najniższa (brak nieporządku) na krańcach (oba końce) i maksymalna (wysoki nieporządek) w środku wykresu.

„Entropia jest stopniem losowości lub niepewności, z kolei zaspokaja cel Data Scientists i modeli ML, aby zmniejszyć niepewność.”
Co to jest Information Gain?
Koncepcja entropii odgrywa ważną rolę w obliczaniu Information Gain.
Information Gain jest stosowany do ilościowego określenia, która cecha zapewnia maksymalną informację o klasyfikacji w oparciu o pojęcie entropii, tj. poprzez kwantyfikację wielkości niepewności, nieuporządkowania lub nieczystości, w ogólności, z zamiarem zmniejszenia ilości entropii inicjującej od góry (węzła korzenia) do dołu (węzłów liści).
Zysk informacji przyjmuje iloczyn prawdopodobieństwa klasy z logiem o podstawie 2 prawdopodobieństwa tej klasy, wzór na entropię jest podany poniżej:
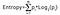
Tutaj „p” oznacza prawdopodobieństwo, które jest funkcją entropii.
Indeks Giniego w działaniu
Indeks Giniego, znany również jako nieczystość Giniego, oblicza wielkość prawdopodobieństwa wystąpienia określonej cechy, która jest sklasyfikowana niepoprawnie przy losowym wyborze. Jeśli wszystkie elementy są związane z jedną klasą to można ją nazwać czystą.
Poznajmy kryterium indeksu Giniego, podobnie jak właściwości entropii, indeks Giniego waha się pomiędzy wartościami 0 i 1, gdzie 0 wyraża czystość klasyfikacji, tzn. wszystkie elementy należą do określonej klasy lub istnieje tam tylko jedna klasa. Natomiast 1 oznacza losowe rozmieszczenie elementów w różnych klasach. Wartość 0.5 wskaźnika Giniego wskazuje na równomierne rozłożenie elementów w niektórych klasach.
Przy projektowaniu drzewa decyzyjnego, preferowane będą cechy posiadające najmniejszą wartość wskaźnika Giniego. Możesz nauczyć się innego algorytmu opartego na drzewie (Random Forest).
Wskaźnik Giniego jest wyznaczany przez odjęcie sumy kwadratów prawdopodobieństw każdej klasy od jednego, matematycznie wskaźnik Giniego może być wyrażony jako:
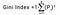
Gdzie Pi oznacza prawdopodobieństwo zaklasyfikowania elementu do odrębnej klasy.
Algorytm drzewa klasyfikacyjnego i regresyjnego (CART) wykorzystuje metodę indeksu Giniego do tworzenia podziałów binarnych.
Dodatkowo, algorytmy drzew decyzyjnych wykorzystują zysk informacyjny do podziału węzła, a indeks Giniego lub entropia jest sposobem ważenia zysku informacyjnego.
Indeks Giniego vs Zysk Informacyjny
Spójrz poniżej na rozbieżność pomiędzy Indeksem Giniego a Zyskiem Informacyjnym,
- Indeks Giniego ułatwia większe dystrybucje tak łatwe do wdrożenia podczas gdy Zysk Informacyjny faworyzuje mniejsze dystrybucje mające małą liczbę z wieloma specyficznymi wartościami.
- Metodę wskaźnika Giniego stosują algorytmy CART, w przeciwieństwie do niej, Information Gain stosuje się w algorytmach ID3, C4.5.
- Indeks Giniego operuje na kategorycznych zmiennych docelowych w kategoriach „sukces” lub „porażka” i dokonuje tylko podziału binarnego, w przeciwieństwie do tego Information Gain oblicza różnicę między entropią przed i po podziale i wskazuje na nieczystość w klasach elementów.
Wniosek
Indeks Giniego i Information Gain są wykorzystywane do analizy scenariusza czasu rzeczywistego, a dane są rzeczywiste, które są przechwytywane z analizy czasu rzeczywistego. W wielu definicjach, to zostało również wymienione jako „zanieczyszczenie danych” lub „jak dane są dystrybuowane. Możemy więc obliczyć, które dane biorą mniej lub więcej udziału w podejmowaniu decyzji.
Dzisiaj kończę z naszymi najlepszymi lekturami:
- Co to jest OpenAI GPT-3?
- Reliance Jio i JioMart: Marketing Strategy, SWOT Analysis, and Working Ecosystem.
- 6 Major Branches of Artificial Intelligence(AI).
- Top 10 Big Data Technologies in 2020
- How is the Analytics Transforming the Hospitality Industry
Oh great, you have made it to the end of this blog! Dziękujemy za przeczytanie!!!!!