

Începând cu Data mining, o abordare unică recent rafinată pentru a fi adoptată cu succes în predicția datelor, este o metodă propice utilizată pentru analiza datelor pentru a descoperi tendințe și conexiuni în date care ar putea arunca interferențe autentice.
Câteva instrumente populare operate în Data mining sunt rețelele neuronale artificiale(ANN), regresia logistică, analiza discriminantă și arborii de decizie.
Arborele de decizie este cel mai cunoscut și mai puternic instrument care este ușor de înțeles și rapid de implementat pentru descoperirea cunoștințelor din seturi de date uriașe și complexe.
Introducere
Numărul de teoreticieni și practicieni retușează cu regularitate tehnicile pentru a face procesul mai riguros, mai adecvat și mai eficient din punct de vedere al costurilor.
Inițial, arborii de decizie sunt utilizați în teoria deciziei și în statistică pe scară largă. Aceștia sunt, de asemenea, instrumente convingătoare în Data mining, recuperarea informațiilor, mineritul de text și recunoașterea modelelor în învățarea automată.
Aici, v-aș recomanda să citiți articolul meu anterior pentru a zăbovi și pentru a vă ascuți fondul de cunoștințe în ceea ce privește arborii de decizie.
Esența arborilor de decizie prevalează în împărțirea seturilor de date în secțiunile sale care, în mod indirect, emerg un arbore de decizie (inversat) având noduri de rădăcini în partea de sus. Modelul stratificat al arborelui de decizie conduce la rezultatul final prin trecerea peste nodurile arborilor.
Aici, fiecare nod cuprinde un atribut (caracteristică) care devine cauza principală a divizării ulterioare în sens descendent.
Puteți răspunde,
- Cum să decideți ce caracteristică ar trebui să fie localizată la nodul rădăcină,
- Cea mai precisă caracteristică pentru a servi ca noduri interne sau noduri de frunze,
- Cum să împărțiți arborele,
- Cum să măsurați precizia divizării arborelui și multe altele.
Există câțiva parametri de divizare fundamentală pentru a aborda problemele considerabile discutate mai sus. Și da, pe tărâmul acestui articol, vom acoperi Entropia, Indicele Gini, Câștigul de informație și rolul lor în executarea tehnicii arborilor de decizie.
În timpul procesului de luare a deciziilor, participă mai multe caracteristici și devine esențial să se preocupe relevanța și consecințele fiecărei caracteristici, atribuind astfel caracteristica corespunzătoare la nodul rădăcină și parcurgând divizarea nodurilor în jos.
Mutarea spre direcția descendentă duce la scăderea nivelului de impuritate și incertitudine și produce o clasificare mai bună sau o divizare de elită la fiecare nod.
Pentru a rezolva același lucru, se folosesc măsuri de divizare cum ar fi Entropia, Câștigul de informație, Indicele Gini, etc.
Definirea entropiei
„Ce este entropia?” În cuvintele lui Lyman, nu este nimic altceva decât măsura dezordinii, sau măsura purității. Practic, este măsurarea impurității sau a hazardului din punctele de date.
Un ordin ridicat de dezordine înseamnă un nivel scăzut de impuritate, permiteți-mi să simplific. Entropia se calculează între 0 și 1, deși, în funcție de numărul de grupuri sau clase prezente în setul de date, ar putea fi mai mare de 1, dar semnifică aceeași semnificație, adică un nivel mai mare de dezordine.
De dragul unei interpretări simple, să limităm valoarea entropiei între 0 și 1.
În imaginea de mai jos, o formă de „U” inversat descrie variația entropiei pe grafic, axa x prezintă punctele de date, iar axa y arată valoarea entropiei. Entropia este cea mai mică (fără dezordine) la extreme (ambele capete) și maximă (dezordine mare) în mijlocul graficului.

„Entropia este un grad de aleatoriu sau de incertitudine, la rândul său, satisface obiectivul cercetătorilor de date și al modelelor ML de a reduce incertitudinea.”
Ce este Câștigul de informație?
Noțiunea de entropie joacă un rol important în calcularea Câștigului de informație.
Câștigul de informație se aplică pentru a cuantifica ce caracteristică oferă informații maxime despre clasificare pe baza noțiunii de entropie, adică prin cuantificarea mărimii incertitudinii, a dezordinii sau a impurității, în general, cu intenția de a diminua cantitatea de entropie inițiată din partea de sus (nodul rădăcină) spre partea de jos (nodurile de frunze).
Câștigul de informație ia produsul probabilităților clasei cu un log având baza 2 a probabilității acelei clase, formula pentru Entropie este dată mai jos:
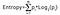
Aici „p” denotă probabilitatea care este o funcție a entropiei.
Indexul Gini în acțiune
Indexul Gini, cunoscut și sub numele de impuritatea Gini, calculează cantitatea de probabilitate ca o anumită caracteristică să fie clasificată incorect atunci când este selectată la întâmplare. Dacă toate elementele sunt legate de o singură clasă, atunci aceasta poate fi numită pură.
Să percepem criteriul indicelui Gini, ca și proprietățile entropiei, indicele Gini variază între valorile 0 și 1, unde 0 exprimă puritatea clasificării, adică Toate elementele aparțin unei clase specificate sau există o singură clasă acolo. Iar 1 indică distribuția aleatorie a elementelor în diferite clase. Valoarea de 0,5 a indicelui Gini arată o distribuție egală a elementelor în anumite clase.
În timpul proiectării arborelui de decizie, caracteristicile care posedă cea mai mică valoare a indicelui Gini vor fi preferate. Puteți învăța un alt algoritm bazat pe arbori (Random Forest).
Indicele Gini se determină prin deducerea sumei pătratelor probabilităților fiecărei clase de la una, matematic, indicele Gini poate fi exprimat astfel:
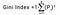
Unde Pi reprezintă probabilitatea ca un element să fie clasificat pentru o clasă distinctă.
Algoritmul de clasificare și arbore de regresie (CART) implementează metoda indicelui Gini pentru a genera diviziuni binare.
În plus, algoritmii arborelui de decizie exploatează câștigul de informație pentru a diviza un nod, iar indicele Gini sau Entropia este pasajul pentru a cântări câștigul de informație.
Indexul Gini vs. Câștigul de informație
Aruncați o privire mai jos pentru a obține discrepanța dintre Indicele Gini și Câștigul de informație,
- Indexul Gini facilitează distribuțiile mai mari atât de ușor de implementat în timp ce Câștigul de informație favorizează distribuțiile mai mici având un număr mic cu mai multe valori specifice.
- Metoda indicelui Gini este utilizată de algoritmii CART, spre deosebire de aceasta, Information Gain este utilizată în algoritmii ID3, C4.5.
- Indicele Gini operează pe variabilele țintă categorice în termeni de „succes” sau „eșec” și efectuează doar divizarea binară, spre deosebire de aceasta, Information Gain calculează diferența dintre entropia înainte și după divizare și indică impuritatea în clasele de elemente.
Concluzie
Indicele Gini și Information Gain sunt utilizate pentru analiza scenariului în timp real, iar datele sunt reale care sunt capturate din analiza în timp real. În numeroase definiții, acesta a fost menționat și ca „impuritatea datelor” sau ” modul în care sunt distribuite datele”. Astfel, putem calcula ce date participă mai puțin sau mai mult la luarea deciziilor.
Astăzi închei cu primele noastre lecturi:
- Ce este OpenAI GPT-3?
- Reliance Jio și JioMart: Strategia de marketing, analiza SWOT și ecosistemul de lucru.
- 6 ramuri majore ale inteligenței artificiale (AI).
- Top 10 tehnologii Big Data în 2020
- Cum transformă analiza industria ospitalității
Oh, minunat, ați ajuns la sfârșitul acestui blog! Vă mulțumim că ați citit!!!!!
.