

Foregående med Data mining, en nyligt raffineret one-size-fits tilgang til at blive vedtaget med succes i dataforudsigelse, er det en gunstig metode, der anvendes til dataanalyse for at opdage tendenser og forbindelser i data, der kan kaste ægte indblanding.
Nogle populære værktøjer, der anvendes i Data mining, er kunstige neurale netværk(ANN), logistikregression, diskriminantanalyse og beslutningstræer.
Beslutningstræet er det mest berygtede og kraftfulde værktøj, der er let at forstå og hurtigt at implementere til videnopdagelse fra store og komplekse datasæt.
Indledning
Antal teoretikere og praktikere ompolerer jævnligt teknikker for at gøre processen mere stringent, hensigtsmæssig og omkostningseffektiv.
I første omgang anvendes beslutningstræer i beslutningsteori og statistik i stor skala. Disse er også overbevisende værktøjer i Data mining, informationssøgning, tekstmining og mønstergenkendelse i maskinlæring.
Her vil jeg anbefale at læse min tidligere artikel for at dvæle og skærpe din videnspulje med hensyn til beslutningstræer.
Kernen i beslutningstræer hersker i at opdele datasættene i sine sektioner, som indirekte fremkommer et beslutningstræ (omvendt) med rødder knuder i toppen. Den stratificerede model af beslutningstræet fører til slutresultatet gennem træernes pass over noder.
Her omfatter hver node en egenskab (feature), der bliver roden til yderligere opdeling i nedadgående retning.
Kan du svare på,
- Hvordan beslutter man, hvilken feature der skal ligge på rodknuden,
- Mest præcise feature til at fungere som interne knuder eller bladknuder,
- Hvordan opdeler man træet,
- Hvordan måler man nøjagtigheden af opdeling af træet og mange flere.
Der er nogle grundlæggende opdelingsparametre til at løse de betydelige problemer, der er drøftet ovenfor. Og ja, inden for denne artikels område vil vi dække Entropi, Gini-indeks, Informationsgevinst og deres rolle i udførelsen af beslutningstræteknikken.
Under beslutningsprocessen deltager flere funktioner, og det bliver vigtigt at bekymre sig om relevansen og konsekvenserne af hver funktion og dermed tildele den passende funktion ved rodknuden og gennemløbe opdelingen af knuder nedad.
Bevægelse mod den nedadgående retning fører til fald i niveauet af urenhed og usikkerhed og giver bedre klassifikation eller eliteopdeling ved hvert knudepunkt.
For at løse det samme anvendes opdelingsforanstaltninger som entropi, informationsgevinst, Gini-indeks osv.
Definition af entropi
“Hvad er entropi?” I Lyman ord, det er intet bare mål for uorden, eller mål for renhed. Dybest set er det måling af urenheden eller tilfældigheden i datapunkterne.
En høj orden af uorden betyder et lavt niveau af urenhed, lad mig forenkle det. Entropi beregnes mellem 0 og 1, selv om det afhængigt af antallet af grupper eller klasser i datasættet kan være større end 1, men det betyder den samme betydning, dvs. højere grad af uorden.
For en enkel fortolknings skyld begrænser vi værdien af entropi mellem 0 og 1.
I nedenstående billede viser en omvendt “U”-form variationen af entropi på grafen, x-aksen viser datapunkterne, og y-aksen viser værdien af entropi. Entropien er lavest (ingen uorden) ved ekstremerne (begge ender) og maksimal (høj uorden) i midten af grafen.

“Entropi er en grad af tilfældighed eller usikkerhed, hvilket igen opfylder datalogers og ML-modellers mål om at reducere usikkerheden.”
Hvad er informationsgevinst?
Begrebet entropi spiller en vigtig rolle i beregningen af informationsgevinst.
Informationsgevinst anvendes til at kvantificere, hvilken funktion der giver maksimal information om klassifikationen baseret på begrebet entropi, dvs. ved at kvantificere størrelsen af usikkerhed, uorden eller urenhed generelt med henblik på at mindske mængden af entropi fra toppen (rodknude) til bunden (bladknuder).
Informationsgevinsten tager produktet af sandsynlighederne for klassen med en log, der har base 2 af denne klasses sandsynlighed, formlen for entropi er givet nedenfor:
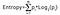
Her betegner “p” sandsynligheden, at det er en funktion af entropi.
Gini-indekset i praksis
Gini-indekset, også kendt som Gini-urenehed, beregner størrelsen af sandsynligheden for, at et bestemt træk klassificeres forkert, når det vælges tilfældigt. Hvis alle elementer er knyttet til en enkelt klasse, kan den kaldes ren.
Lad os opfatte kriteriet for Gini-indekset, ligesom entropiens egenskaber varierer Gini-indekset mellem værdierne 0 og 1, hvor 0 udtrykker renhed i klassifikationen, dvs. alle elementer tilhører en bestemt klasse, eller der findes kun én klasse. Og 1 angiver den tilfældige fordeling af elementerne på forskellige klasser. Værdien 0,5 af Gini-indekset viser en ligelig fordeling af elementer på nogle klasser.
Ved udformningen af beslutningstræet vil de træk, der har den mindste værdi af Gini-indekset, blive foretrukket. Du kan lære en anden træbaseret algoritme (Random Forest).
Gini-indekset bestemmes ved at trække summen af kvadratet af sandsynlighederne for hver klasse fra én, matematisk kan Gini-indekset udtrykkes som:
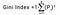
Hvor Pi angiver sandsynligheden for, at et element klassificeres til en bestemt klasse.
Klassifikations- og regressionstræ (CART)-algoritmen anvender Gini-indekset som metode til at skabe binære opdelinger.
Dertil kommer, at beslutningstræalgoritmer udnytter informationsgevinsten til at opdele en knude, og Gini-indekset eller entropi er den vej til at vægte informationsgevinsten.
Gini Indeks vs Information Gain
Se nedenfor for at få diskrepans mellem Gini Indeks og Information Gain,
- Gini Indekset letter de større fordelinger så let at implementere, mens Information Gain favoriserer mindre fordelinger med lille antal med flere specifikke værdier.
- Metoden med Gini-indekset anvendes af CART-algoritmer, i modsætning hertil anvendes Informationsgevinst i ID3- og C4.5-algoritmer.
- Gini-indekset opererer på de kategoriske målvariabler i form af “succes” eller “fiasko” og udfører kun binær opdeling, i modsætning hertil beregner Information Gain forskellen mellem entropi før og efter opdelingen og angiver urenheden i klasser af elementer.
Slutning
Gini-indekset og Information Gain anvendes til analyse af realtidsscenariet, og data er reelle, der er opfanget fra realtidsanalysen. I talrige definitioner er det også blevet nævnt som “dataenes urenhed” eller ” hvordan data er fordelt”. Så vi kan beregne, hvilke data der tager mindre eller mere del i beslutningstagningen.
I dag slutter jeg af med vores toplæsninger:
- Hvad er OpenAI GPT-3?
- Reliance Jio og JioMart: Marketingstrategi, SWOT-analyse og arbejdsøkosystem.
- 6 Major Branches of Artificial Intelligence(AI): 6 Major Branches of Artificial Intelligence(AI).
- Top 10 Big Data-teknologier i 2020
- Hvordan er Analytics ved at transformere hotelbranchen
Oh fantastisk, du er nået til slutningen af denne blog! Tak fordi du læste!!!!!