
TLDR: Indeksering er bare en måde at gruppere dokumenter på, opdele samlinger i grupper for at fremskynde ydelsen
Overblik
Indekser øger forespørgselsydelsen, ligesom det bruges til søgninger
Ideen med indeksering i MongoDB svarer til indekset i en bog, de øger hastigheden for at finde en side. Indekset i MongoDB øger hastigheden på at finde dokumenter
Hvordan fungerer indekser?
Først skal vi forstå, hvordan du erklærer indeks i MongoDB
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Her er feltet “fieldName”, som vil blive indekseret. “Value” kan være -1 eller 1 eller “text”.
Det definerer typen af indeks, 1 eller -1 øger find() forespørgselsydelse, mens “text” bruges til søgning.
1 og -1 giver rækkefølgen af indekset. Ascending = -1 & Descending =1
Nu, hvordan indekser fungerer under kølerhjelmen?
Forestil dig en samling af brugere, hvor hvert dokument indeholder forskellige oplysninger, hvoraf en af dem er score.
Lad os sige, at vi ønsker, at alle brugere skal score 23.
Når der ikke findes noget indeks, går MongoDB gennem hvert dokument for at finde det forespurgte dokument, Dette kaldes Collection scan, MongoDB har en forkortelse for dette COLLSCAN (Dette kaldes Table scan i Relationelle databaser)
Hvordan kan vi optimere dette?
For at optimere dette kan vi oprette en tabel med en kolonne for score og en anden kolonne for referencer, som vil indeholde ID’er for dokumenter med den pågældende score. Nu behøver vi kun at scanne denne tabel i stedet for at scanne hele databasen. Dette er meget hurtigere. Dette er præcis, hvad et indeks er.
Indekser hjælper MongoDB med at indsnævre det datasæt, som den skal scanne. Dette kaldes Index Scan, MongoDB har også en forkortelse for dette IXNSCAN
Her er en visuel repræsentation af et scoreindeks og dets mapping.
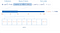
Præstationsforbedring ved indeks er kun synlig, når antallet af dokumenter krydser 100K eller deromkring.
Du kan selv sammenligne det ved at sammenligne to forespørgsler, en med et indekseret felt og en uden indeks
db.<collection name>.find(query).explain()
Et objekt vil blive returneret
object.winingPlan.stage vil fortælle typen af scanning COLLSCAN eller IXNSCAN
men det vil ikke fortælle dig den tid, der er taget i udførelsen
brug explain(‘executionStat’)-metoden før forespørgselsmetoden som find
db.<collection name>explain('executionStat').find(query)

executionTimeMillis vil fortælle dig den tid, der er taget i udførelsen
Nedsider af indeks
Indekser er ikke gratis, Indekser koster plads. Indekser kan øge læsehastigheden, men når der skrives noget, skal indekset opdateres for at løse dette bruger vi B-træ vi laver nogle beregninger før indsættelse, så det er hurtigere.
B-træ
Indekser er ikke en tabel med grupper, konceptuelt er det faktisk et B-træ (binært træ) ikke kun MongoDB, SQL-database bruger også B-træ til indeksering
Denne video forklarer bedst B-træ