
Det anbefales, at du forstår, hvad et neuralt netværk er, før du læser denne artikel. I Processen med at opbygge et neuralt netværk er et af de valg, du kommer til at træffe, hvilken aktiveringsfunktion der skal bruges i det skjulte lag såvel som i netværkets outputlag. Denne artikel diskuterer nogle af de valg.
Elementer i et neuralt netværk :-
Inputlag :- Dette lag accepterer inputfunktioner. Det giver oplysninger fra omverdenen til netværket, der udføres ingen beregning i dette lag, knuderne her videregiver blot oplysningerne (funktioner) til det skjulte lag.
Det skjulte lag :- Knuderne i dette lag er ikke udsat for den ydre verden, de er den del af den abstraktion, som et neuralt netværk giver. Det skjulte lag udfører alle former for beregninger på de funktioner, der er indtastet via indgangslaget, og overfører resultatet til udgangslaget.
Udgangslaget :- Dette lag bringer de oplysninger, som netværket har lært, op til den ydre verden.
Hvad er en aktiveringsfunktion, og hvorfor skal man bruge dem?
Definition af aktiveringsfunktion:- Aktiveringsfunktionen afgør, om en neuron skal aktiveres eller ej, ved at beregne den vægtede sum og yderligere tilføje bias med den. Formålet med aktiveringsfunktionen er at indføre ikke-linearitet i et neurons output.
Forklaring :-
Vi ved, at neurale netværk har neuroner, der arbejder i overensstemmelse med vægt, bias og deres respektive aktiveringsfunktion. I et neuralt netværk ville vi opdatere neuronernes vægte og bias på baggrund af fejlen ved udgangen. Denne proces er kendt som back-propagation. Aktiveringsfunktioner gør back-propagation mulig, da gradienterne leveres sammen med fejlen til at opdatere vægtene og biaserne.
Hvorfor har vi brug for ikke-lineære aktiveringsfunktioner :-
Et neuralt netværk uden en aktiveringsfunktion er i bund og grund blot en lineær regressionsmodel. Aktiveringsfunktionen foretager den ikke-lineære transformation af input, hvilket gør den i stand til at lære og udføre mere komplekse opgaver.
Matematisk bevis :-
Sæt, at vi har et neuralt net som dette :-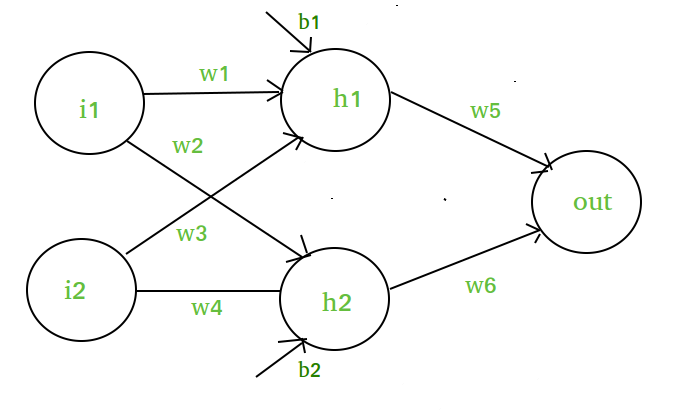
Elementer i diagrammet :-
Det skjulte lag, dvs. lag 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Her er
- z(1) det vektoriserede output af lag 1
- W(1) de vektoriserede vægte, der er tildelt neuronerne
i det skjulte lag i.e. w1, w2, w3 og w4- X er de vektoriserede inputfunktioner, dvs. i1 og i2
- b er den vektoriserede bias, der tildeles neuroner i det skjulte
lag, dvs. b1 og b2- a(1) er den vektoriserede form af en hvilken som helst lineær funktion.
(Bemærk: Vi overvejer ikke aktiveringsfunktion her)
Lag 2, dvs. outputlag :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Beregning i outputlaget:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Denne observation resulterer igen i en lineær funktion, selv efter anvendelse af et skjult lag, og derfor kan vi konkludere, at uanset hvor mange skjulte lag vi vedhæfter i det neurale net, vil alle lag opføre sig på samme måde, fordi sammensætningen af to lineære funktioner selv er en lineær funktion. En neuron kan ikke lære med blot en lineær funktion tilknyttet den. En ikke-lineær aktiveringsfunktion vil lade den lære efter forskellen i forhold til fejl.
Derfor har vi brug for en aktiveringsfunktion.
VARIER AF AKTIVATIONSFUNKTIONER:-
1). Lineær funktion :-
- Ligning : Lineær funktion har en ligning, der svarer til en lige linje, dvs. y = ax
- Uanset hvor mange lag vi har, hvis alle er lineære af natur, er den endelige aktiveringsfunktion i det sidste lag intet andet end blot en lineær funktion af input fra første lag.
- Område : -inf til +inf
- Anvendelse : Lineær aktiveringsfunktion anvendes kun ét sted, nemlig i.
- Problemer : Hvis vi differentierer den lineære funktion for at skabe ikke-linearitet, vil resultatet ikke længere afhænge af input “x”, og funktionen vil blive konstant, og det vil ikke indføre nogen banebrydende adfærd i vores algoritme.
For eksempel : Beregning af prisen på et hus er et regressionsproblem. Husprisen kan have en hvilken som helst stor/små værdi, så vi kan anvende lineær aktivering i outputlaget. Selv i dette tilfælde skal det neurale net have en ikke-lineær funktion i de skjulte lag.
2). Sigmoidfunktion :-
- Det er en funktion, der er plottet som en S-formet graf.
- Ligning :
A = 1/(1 + e-x) - Beskaffenhed : Ikke-lineær. Bemærk, at X-værdierne ligger mellem -2 til 2, Y-værdierne er meget stejle. Det betyder, at små ændringer i x også vil medføre store ændringer i værdien af Y.
- Værdiområde : 0 til 1
- Anvendelse : Bruges normalt i outputlaget i en binær klassifikation, hvor resultatet enten er 0 eller 1, da værdien for sigmoidfunktionen kun ligger mellem 0 og 1, så resultatet kan let forudsiges at blive 1, hvis værdien er større end 0,5 og 0 ellers.
3). Tanh-funktion :- Den aktivering, der næsten altid virker bedre end sigmoid-funktionen, er Tanh-funktionen også kendt som tangent hyperbolisk funktion. Det er faktisk en matematisk forskudt version af sigmoidfunktionen. Begge ligner hinanden og kan afledes af hinanden.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Værdiområde :- -1 til +1
- Natur :- Ikke-lineær
- Anvendelse :- Bruges normalt i skjulte lag i et neuralt netværk, da dens værdier ligger mellem -1 og 1, hvorfor middelværdien for det skjulte lag kommer ud på 0 eller meget tæt på det, hvilket hjælper med at centrere dataene ved at bringe middelværdien tæt på 0. Dette gør indlæringen af det næste lag meget lettere.
- Ligning :- A(x) = max(0,x). Den giver et output x, hvis x er positiv og 0 ellers.
- Værdiområde :- [0, inf)
- Natur :- Ikke-lineær, hvilket betyder, at vi nemt kan backpropagere fejlene og have flere lag af neuroner, der aktiveres af ReLU-funktionen.
- Anvendelse :- ReLu er mindre beregningsmæssigt dyrt end tanh og sigmoid, fordi det involverer enklere matematiske operationer. På et tidspunkt aktiveres kun nogle få neuroner, hvilket gør netværket sparsomt, hvilket gør det effektivt og let for beregning.
4). RELU :- Står for Rectified linear unit. Det er den mest almindeligt anvendte aktiveringsfunktion. Primært implementeret i skjulte lag af neurale netværk.
Med enkle ord lærer RELU meget hurtigere end sigmoid og Tanh-funktionen.
5). Softmax-funktion :- Softmax-funktionen er også en type sigmoid-funktion, men er praktisk, når vi forsøger at håndtere klassifikationsproblemer.
- Natur :- Ikke-lineær
- Anvendelsesområder :- Bruges normalt, når vi forsøger at håndtere flere klasser. Softmax-funktionen vil klemme udgangene for hver klasse mellem 0 og 1 og vil også dividere med summen af udgangene.
- Output :- Softmax-funktionen bruges ideelt set i klassifikatorens outputlag, hvor vi faktisk forsøger at opnå de sandsynligheder, der skal definere klassen for hvert input.
- Den grundlæggende tommelfingerregel er, at hvis du virkelig ikke ved, hvilken aktiveringsfunktion du skal bruge, så brug blot RELU, da det er en generel aktiveringsfunktion og bruges i de fleste tilfælde i dag.
- Hvis dit output er til binær klassifikation, er sigmoidfunktionen et meget naturligt valg til outputlaget.
VIDERE DEN RIGTIGE AKTIVATIONSFUNKTION
Fodnote :-
Aktiveringsfunktionen foretager den ikke-lineære transformation af input, hvilket gør den i stand til at lære og udføre mere komplekse opgaver.