

Med början av Data mining, en nyligen förfinad one-size-fits approach för att framgångsrikt antas i dataprediktion, är det en gynnsam metod som används för dataanalys för att upptäcka trender och kopplingar i data som kan kasta äkta störningar.
Några populära verktyg som används vid datautvinning är artificiella neurala nätverk (ANN), logistisk regression, diskriminantanalys och beslutsträd.
Beslutsträdet är det mest kända och kraftfulla verktyget som är lätt att förstå och snabbt att implementera för kunskapsupptäckt från stora och komplexa datamängder.
Introduktion
Antalet teoretiker och praktiker ompolerar regelbundet tekniker för att göra processen mer rigorös, adekvat och kostnadseffektiv.
Initialt används beslutsträd inom beslutsteori och statistik i stor skala. Dessa är också övertygande verktyg i Data mining, informationssökning, text mining och mönsterigenkänning i maskininlärning.
Här skulle jag rekommendera att läsa min tidigare artikel för att stanna kvar och skärpa din kunskapspool när det gäller beslutsträd.
Kärnan i beslutsträd råder i att dela upp datamängderna i sina sektioner som indirekt framträder ett beslutsträd (inverterat) med rötter noder på toppen. Beslutsträdens stratifierade modell leder till slutresultatet genom att trädens noder passerar över.
Här omfattar varje nod ett attribut (funktion) som blir grundorsaken till ytterligare uppdelning i nedåtgående riktning.
Kan du svara på,
- Hur man bestämmer vilken egenskap som ska ligga vid rotnoden,
- Den mest exakta egenskapen som ska fungera som interna noder eller bladnoder,
- Hur man delar upp trädet,
- Hur man mäter noggrannheten i uppdelning av träd och många fler.
Det finns några grundläggande delningsparametrar för att lösa de betydande problem som diskuterats ovan. Och ja, inom ramen för den här artikeln kommer vi att täcka entropi, Gini-index, informationsvinst och deras roll i utförandet av tekniken för beslutsträd.
Under beslutsprocessen deltar flera funktioner och det blir viktigt att ta hänsyn till relevansen och konsekvenserna av varje funktion, vilket innebär att man tilldelar den lämpliga funktionen vid rotnoden och går igenom uppdelningen av noderna nedåt.
Förflyttning mot nedåtgående riktning leder till minskad orenhet och osäkerhet och ger bättre klassificering eller elituppdelning i varje nod.
För att lösa samma sak används uppdelningsmått som t.ex. entropi, informationsvinst, Gini-index, etc.
Definiering av entropi
”Vad är entropi?” Med Lymans ord är det inget annat än måttet på oordning, eller måttet på renhet. I grund och botten är det ett mått på orenhet eller slumpmässighet i datapunkterna.
En hög ordning av oordning innebär en låg nivå av orenhet, låt mig förenkla det. Entropin beräknas mellan 0 och 1, även om den beroende på antalet grupper eller klasser som finns i datamängden kan vara större än 1, men det betyder samma sak, dvs. högre grad av oordning.
För en enkel tolknings skull, låt oss begränsa värdet av entropin mellan 0 och 1.
I nedanstående bild visar en omvänd U-form variationen av entropin i grafen, x-axeln visar datapunkterna och y-axeln visar värdet av entropin. Entropin är lägst (ingen oordning) vid ytterligheterna (båda ändarna) och högst (hög oordning) i mitten av grafen.

”Entropi är en grad av slumpmässighet eller osäkerhet, vilket i sin tur uppfyller datavetarnas och ML-modellernas mål att minska osäkerheten.”
Vad är informationsvinst?
Begreppet entropi spelar en viktig roll vid beräkning av informationsvinst.
Informationsvinst tillämpas för att kvantifiera vilken funktion som ger maximal information om klassificeringen utifrån begreppet entropi, dvs. genom att kvantifiera storleken på osäkerhet, oordning eller orenhet, i allmänhet, med avsikt att minska mängden entropi från toppen (rotnod) till botten (bladnoder).
Informationsvinsten tar produkten av sannolikheterna för klassen med en log som har bas 2 av den klassens sannolikhet, formeln för entropi ges nedan:
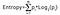
Här betecknar ”p” sannolikheten att det är en funktion av entropin.
Gini-index i praktiken
Gini-index, även känt som Ginis orenhet, beräknar hur stor sannolikheten är för att en viss funktion klassificeras felaktigt när den väljs ut slumpmässigt. Om alla element är kopplade till en enda klass kan den kallas ren.
Låt oss uppfatta kriteriet för Gini-index, liksom entropins egenskaper varierar Gini-index mellan värdena 0 och 1, där 0 uttrycker renhet i klassificeringen, dvs. alla element tillhör en specificerad klass eller endast en klass finns där. Och 1 anger en slumpmässig fördelning av element över olika klasser. Värdet 0,5 på Gini-indexet visar en jämn fördelning av element över vissa klasser.
Vid utformningen av beslutsträdet kommer de egenskaper som har det lägsta värdet på Gini-indexet att föredras. Du kan lära dig en annan trädbaserad algoritm (Random Forest).
Gini-indexet bestäms genom att subtrahera summan av kvadraten av sannolikheterna för varje klass från en, matematiskt kan Gini-indexet uttryckas som:
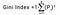
Varvid Pi anger sannolikheten för att ett element ska klassificeras för en distinkt klass.
CART-algoritmen (Classification and Regression Tree) använder Gini-index som metod för att skapa binära uppdelningar.
Det är dessutom så att beslutsträdsalgoritmer utnyttjar informationsvinsten för att dela upp en nod, och Gini-index eller entropi är en metod för att väga informationsvinsten.
Gini Index vs Information Gain
Ta en titt nedan för att se skillnaden mellan Gini Index och Information Gain,
- Gini Index underlättar större fördelningar som är lätta att genomföra medan Information Gain gynnar mindre fördelningar som har ett litet antal med flera specifika värden.
- Metoden Gini-index används av CART-algoritmerna, medan informationsvinsten används i ID3- och C4.5-algoritmerna.
- Gini-indexet arbetar med kategoriska målvariabler i termer av ”framgång” eller ”misslyckande” och utför endast binär uppdelning, i motsats till detta beräknar Information Gain skillnaden mellan entropin före och efter uppdelningen och indikerar orenhet i klasser av element.
Slutsats
Gini-indexet och Information Gain används för analysen av scenariet i realtid, och data är riktiga som fångas upp från analysen i realtid. I många definitioner har det också nämnts som ”orenhet av data” eller ”hur data distribueras”. Så vi kan beräkna vilka data som tar mindre eller mer del i beslutsfattandet.
I dag slutar jag med våra toppläsningar:
- Vad är OpenAI GPT-3?
- Reliance Jio och JioMart: Marknadsföringsstrategi, SWOT-analys och fungerande ekosystem.
- 6 stora grenar av artificiell intelligens (AI).
- Top 10 Big Data Technologies in 2020
- Hur omvandlar analysen hotellbranschen
Oh bra, du har tagit dig till slutet av den här bloggen! Tack för att du läste!!!!!