
TLDR: Indexering är bara ett sätt att gruppera dokument, dela upp samlingar i grupper för att öka prestandan
Översikt
Index ökar prestanda för förfrågningar samt används för sökningar
Idén med indexering i MongoDB liknar indexet i en bok, de ökar hastigheten för att hitta en sida. Indexet i MongoDB ökar hastigheten för att hitta dokument
Hur fungerar index?
Först ska vi förstå hur du deklarerar index i MongoDB
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Här är fältet ”fieldName” som ska indexeras. ”Value” kan vara -1 eller 1 eller ”text”.
Det definierar typen av index, 1 eller -1 ökar find()-förfrågningens prestanda medan ”text” används för sökning.
1 och -1 ger indexets ordning. Uppåtgående = -1 & Nedåtgående =1
Nu, hur indexen fungerar under huven?
Föreställ dig en samling användare, varje dokument innehåller olika information, en av dem är poäng.
Säg att vi vill att alla användare ska få 23 poäng.
När inget index finns går MongoDB igenom varje dokument för att hitta det efterfrågade dokumentet, detta kallas Collection scan, MongoDB har en förkortning för detta COLLSCAN (Detta kallas Table scan i relationsdatabaser)
Hur kan vi optimera detta?
För att optimera detta kan vi skapa en tabell med en kolumn för score och en annan kolumn för referenser som kommer att innehålla ID:n på dokumenten med den specifika poängen. Nu behöver vi bara skanna den tabellen i stället för att skanna hela databasen. Detta är mycket snabbare. Detta är precis vad ett index är.
Index hjälper MongoDB att begränsa den datamängd som måste skannas. Detta kallas Index Scan, MongoDB har en förkortning för detta också IXNSCAN
Här är en visuell representation av ett poängindex och dess mappning.
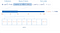
Prestationsförbättring genom index är endast synlig när antalet dokument passerar 100K eller så.
Du kan jämföra det själv genom att jämföra två förfrågningar, en med ett indexerat fält och en utan index
db.<collection name>.find(query).explain()
Ett objekt kommer att returneras
object.winingPlan.stage kommer att berätta vilken typ av skanning COLLSCAN eller IXNSCAN
men den kommer inte att berätta hur lång tid det tar att utföra
använd explain(’executionStat’)-metoden före frågemetoden som find
.
db.<collection name>explain('executionStat').find(query)

executionTimeMillis kommer att tala om hur lång tid det tar att utföra en handling
Neddelar med index
Index är inte gratis, Index kostar utrymme. Index kan öka läshastigheten, men när något skrivs måste indexet uppdateras för att lösa detta använder vi B-trädet, vi gör vissa beräkningar före insättning så att det går snabbare.
B-träd
Index är inte en tabell med grupper, begreppsmässigt är det faktiskt ett B-träd (binärt träd) inte bara MongoDB, SQL-databasen använder också B-träd för indexering
Denna video förklarar bäst B-trädet