
On suositeltavaa ymmärtää, mikä on neuroverkko ennen tämän artikkelin lukemista. Neuraaliverkon rakentamisessa yksi valinnoista, jonka saat tehdä, on se, mitä aktivointifunktiota käytät verkon piilotetussa kerroksessa sekä ulostulokerroksessa. Tässä artikkelissa käsitellään joitakin näistä valinnoista.
Neuraaliverkon elementit :-
Syöttökerros :- Tämä kerros ottaa vastaan syöttöominaisuuksia. Se antaa tietoa ulkomaailmasta verkolle, tässä kerroksessa ei suoriteta mitään laskentaa, solmut tässä vain välittävät tietoa (piirteitä) piilokerrokseen.
Kätketty kerros :- Tämän kerroksen solmut eivät ole alttiina ulkomaailmalle, ne ovat osa minkä tahansa neuroverkon tarjoamaa abstraktiota. Piilotettu kerros suorittaa kaikenlaisia laskutoimituksia syöttökerroksen kautta syötetyille piirteille ja siirtää tuloksen lähtökerrokseen.
Lähtökerros :- Tämä kerros tuo verkon oppimat tiedot ulkomaailmaan.
Mikä on aktivointifunktio ja miksi niitä käytetään?
Aktivointifunktion määritelmä:- Aktivointifunktio päättää, pitäisikö neuroni aktivoida vai ei laskemalla painotetun summan (weighted sum) ja lisäämällä siihen vielä biasin. Aktivointifunktion tarkoituksena on tuoda epälineaarisuutta neuronin ulostuloon.
Esittely :-
Tiedämme, että neuroverkossa on neuroneja, jotka toimivat painon, biasin ja niitä vastaavan aktivointifunktion mukaisesti. Neuroverkossa päivitämme neuronien painot ja harhat ulostulon virheen perusteella. Tämä prosessi tunnetaan nimellä back-propagation. Aktivointifunktiot mahdollistavat back-propagationin, koska gradientit toimitetaan yhdessä virheen kanssa painojen ja biasien päivittämiseen.
Miksi tarvitsemme epälineaarisia aktivointifunktioita :-
Neuraaliverkko ilman aktivointifunktiota on pohjimmiltaan vain lineaarinen regressiomalli. Aktivointifunktio tekee ei-lineaarisen muunnoksen syötteelle, jolloin se kykenee oppimaan ja suorittamaan monimutkaisempia tehtäviä.
Matemaattinen todistus :-
Esitettäköön, että meillä on tällainen neuroverkko :-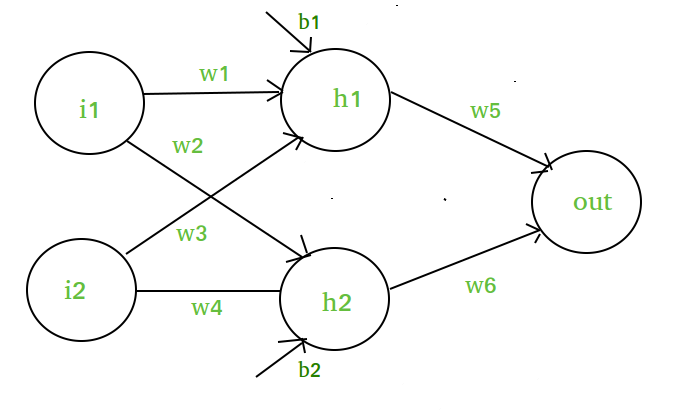
Kaavion elementit :-
Kätketty kerros ts. kerros 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Tässä
- z(1) on kerroksen 1 vektorimuotoinen ulostulo
- W(1) on piilotetun kerroksen i:n neuroneille
annetut vektorimuotoiset painot.e. w1, w2, w3 ja w4- X ovat vektoroidut tulo-ominaisuudet ts. i1 ja i2
- b on piilevän
kerroksen neuroneille määritetyt vektoroidut painotukset eli b1 ja b2- a(1) on minkä tahansa lineaarisen funktion vektoroitu muoto.
(Huom.: Emme käsittele tässä aktivointifunktiota)
Kerros 2 ts. ulostulokerros :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Laskelma ulostulokerroksessa:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Tämän havainnon tuloksena on jälleen lineaarinen funktio myös piilotetun kerroksen soveltamisen jälkeen, joten voimme päätellä, että, ei ole väliä kuinka monta piilotettua kerrosta liitämme neuraaliverkkoon, kaikki kerrokset käyttäytyvät samalla tavalla, koska kahden lineaarisen funktion kompositio on lineaarinen funktio itse. Neuroni ei voi oppia pelkällä siihen liitetyllä lineaarisella funktiolla. Epälineaarinen aktivointifunktio antaa sen oppia eron mukaan suhteessa virheeseen.
Siten tarvitsemme aktivointifunktion.
AKTIVOINTIFUNKTION VAIHTOEHDOT :-
1). Lineaarinen funktio :-
- Yhtälö : Lineaarisen funktion yhtälö on samanlainen kuin suoralla eli y = ax
- Ei ole väliä kuinka monta kerrosta meillä on, jos kaikki ovat luonteeltaan lineaarisia, viimeisen kerroksen lopullinen aktivointifunktio ei ole mitään muuta kuin pelkkä lineaarinen funktio ensimmäisen kerroksen syötteestä.
- Vaihteluväli : -inf ja +inf välillä
- Käyttökohteet : Lineaarista aktivaatiofunktiota käytetään vain yhdessä paikassa i.eli ulostulokerroksessa.
- Ongelmat : Jos eriytämme lineaarista funktiota tuodaksemme epälineaarisuutta, tulos ei enää riipu syötteestä ”x” ja funktiosta tulee vakio, se ei tuo mitään mullistavaa käyttäytymistä algoritmiimme.
Esimerkki : Talon hinnan laskeminen on regressio-ongelma. Talon hinta voi olla mikä tahansa suuri/pieni arvo, joten voimme soveltaa lineaarista aktivointia ulostulokerroksessa. Tässäkin tapauksessa neuroverkolla on oltava jokin epälineaarinen funktio piilokerroksissa.
2). Sigmoidifunktio :-
- Se on funktio, joka piirretään S:n muotoisena kuvaajana.
- Yhtälö :
A = 1/(1 + e-x) - Luonne : Ei-lineaarinen. Huomaa, että X-arvot ovat välillä -2-2, Y-arvot ovat hyvin jyrkkiä. Tämä tarkoittaa, että pienet muutokset x:ssä aiheuttavat suuria muutoksia myös Y:n arvossa.
- Arvoalue : 0-1
- Käyttökohteet : Käytetään yleensä binäärisen luokittelun ulostulokerroksessa, jossa tulos on joko 0 tai 1, koska sigmoidifunktion arvo on vain 0:n ja 1:n välissä, joten tuloksen voidaan helposti ennustaa olevan 1, jos arvo on suurempi kuin 0,5, ja muuten 0.
3). Tanh-funktio :- Aktivointi, joka toimii lähes aina paremmin kuin sigmoidifunktio, on Tanh-funktio, joka tunnetaan myös nimellä Tangent Hyperbolic function. Se on itse asiassa matemaattisesti siirretty versio sigmoidifunktiosta. Molemmat ovat samankaltaisia ja ne voidaan johtaa toisistaan.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Arvoalue :- -1:stä +1:een
- Luonne :- epälineaarinen
- Käyttökohteet :- Käytetään yleensä neuroverkon piilotetuissa kerroksissa, koska sen arvot ovat -1:n ja 1:n välissä, joten piilotetun kerroksen keskiarvo saadaan 0:ksi tai hyvin lähelle sitä. Tämä helpottaa seuraavan kerroksen oppimista huomattavasti.
- Yhtälö :- A(x) = max(0,x). Se antaa ulostulon x, jos x on positiivinen ja 0 muuten.
- Arvoalue :- [0, inf)
- Luonne :- ei-lineaarinen, mikä tarkoittaa, että voimme helposti backpropagoida virheitä ja saada useita kerroksia neuroneja aktivoitua ReLU-funktiolla.
- Käyttökohteet :- ReLu on laskennallisesti vähemmän kallis kuin tanh ja sigmoidi, koska siihen liittyy yksinkertaisempia matemaattisia operaatiota. Kerrallaan vain muutama neuroni aktivoituu, mikä tekee verkosta harvan tehden siitä tehokkaan ja helpon laskennan.
4). RELU :- Tarkoittaa oikaistua lineaarista yksikköä. Se on yleisimmin käytetty aktivointifunktio. Toteutetaan pääasiassa neuroverkon piilokerroksissa.
Yksinkertaisesti sanottuna RELU oppii paljon nopeammin kuin sigmoid- ja Tanh-funktio.
5). Softmax-funktio :- Softmax-funktio on myös eräänlainen sigmoidifunktio, mutta se on kätevä, kun yritämme käsitellä luokitusongelmia.
- Luonne :- epälineaarinen
- Käyttökohteet :- Käytetään yleensä, kun yritetään käsitellä useita luokkia. Softmax-funktio puristaa kunkin luokan ulostulot välillä 0 ja 1 ja jakaa myös ulostulojen summan.
- Tulos :- Softmax-funktiota käytetään ihanteellisesti luokittimen ulostulokerroksessa, jossa itse asiassa yritämme saavuttaa todennäköisyyksiä kunkin syötteen luokan määrittämiseksi.
- Perussääntö on, että jos et todellakaan tiedä, mitä aktivaatiofunktiota käyttäisit, käytä yksinkertaisesti RELU:ta, koska se on yleinen aktivaatiofunktio ja sitä käytetään nykyään useimmissa tapauksissa.
- Jos ulostulosi on binääriluokittelua varten, sigmoidifunktio on hyvin luonnollinen valinta ulostulokerrokseen.
OIKEAN AKTIVOINTIFUNKTION VALINTA
Jalkahuomautus :-
Aktivointifunktio tekee epälineaarisen transformaation syötteeseen tehden siitä kyvykkäämmän oppimaan ja suorittamaan monimutkaisempia tehtäviä.