
Alkaen tiedonlouhinnasta, hiljattain jalostetusta yhden koon sopivasta lähestymistavasta, joka voidaan ottaa menestyksekkäästi käyttöön datan ennustamisessa, se on suotuisa menetelmä, jota käytetään data-analyysissä havaitsemaan trendejä ja yhteyksiä datassa, jotka saattavat heittää aitoja häiriöitä.
Joitakin suosittuja työkaluja, joita käytetään tiedonlouhinnassa, ovat keinotekoiset neuroverkot (ANN), logistinen regressio, diskriminaatioanalyysi ja päätöspuut.
Päätöspuu on tunnetuin ja tehokkain työkalu, joka on helppo ymmärtää ja nopea toteuttaa tiedon löytämiseksi valtavista ja monimutkaisista tietokokonaisuuksista.
Sisällysluettelo
Teoreetikot ja käytännön toimijat hiovat tekniikoita säännöllisesti uudelleen, jotta prosessista saataisiin tiukempi, riittävämpi ja kustannustehokkaampi.
Alun perin päätöspuita käytetään päätösteoriassa ja tilastotieteessä laajamittaisesti. Ne ovat myös pakottavia työkaluja tiedonlouhinnassa, tiedonhaussa, tekstinlouhinnassa ja hahmontunnistuksessa koneoppimisessa.
Tässä suosittelen lukemaan aikaisemman artikkelini, jotta voit viipyä ja terävöittää tietämyksesi päätöspuiden osalta.
Päätöksentekopuiden ydin vallitsee jakamalla tietokokonaisuudet osioihinsa, jotka epäsuorasti kehittyvät päätöksentekopuuksi (käänteinen), jolla on juurisolmut ylhäällä. Päätöksentekopuun ositettu malli johtaa lopputulokseen puiden solmujen ylimenevien solmujen kautta.
Tässä jokainen solmu käsittää attribuutin (ominaisuuden), josta tulee alaspäin suuntautuvan jakamisen juurisyy.
Voitko vastata,
- Miten päätetään, mikä piirre tulisi sijoittaa juurisolmuun,
- Tarkin piirre toimimaan sisäisinä solmuina tai lehtisolmuina,
- Miten puun jakaminen tapahtuu,
- Miten puun jakamisen tarkkuutta mitataan ja paljon muuta.
On olemassa joitakin perustavanlaatuisia jakopuun parametreja, joiden avulla voidaan käsitellä edellä käsiteltyjä huomattavia kysymyksiä. Ja kyllä, tämän artikkelin alueella käsittelemme entropiaa, Gini-indeksiä, informaatiovoittoa ja niiden roolia päätöspuutekniikan suorittamisessa.
Päätöksentekoprosessin aikana useita piirteitä osallistuu, ja on välttämätöntä huolehtia kunkin piirteen merkityksestä ja seurauksista, jolloin asianmukainen piirre osoitetaan juurisolmuun ja kuljetaan solmujen jakaminen alaspäin.
Liikkuminen alaspäin johtaa epäpuhtauksien ja epävarmuuden vähenemiseen ja johtaa parempaan luokitteluun tai eliittijakoon kussakin solmussa.
Saman ratkaisemiseksi käytetään jakomittoja, kuten entropiaa, informaatiovoittoa, Gini-indeksiä jne.
Entropian määrittely
”Mikä on entropia?”. Lymanin sanoin, se ei ole mitään muuta kuin epäjärjestyksen mitta tai puhtauden mitta. Periaatteessa se on datapisteiden epäpuhtauden tai satunnaisuuden mittaaminen.
Suuri epäjärjestyksen määrä tarkoittaa pientä epäpuhtautta, yksinkertaistan asiaa. Entropia lasketaan 0:n ja 1:n väliltä, vaikka riippuen aineistossa esiintyvien ryhmien tai luokkien määrästä se voi olla suurempi kuin 1, mutta se merkitsee samaa merkitystä, eli korkeampaa epäjärjestyksen tasoa.
Yksinkertaisen tulkinnan vuoksi rajataan entropian arvo 0:n ja 1:n välille.
Alla olevassa kuvassa käänteinen U-muoto kuvaa entropian vaihtelua kuvaajassa, x-akselilla esitetään datapisteet ja y-akselilla entropian arvo. Entropia on pienimmillään (ei epäjärjestystä) ääripäissä (molemmissa päissä) ja suurimmillaan (suuri epäjärjestys) kuvaajan keskellä.

”Entropia on sattumanvaraisuuden tai epävarmuuden astetta, joka puolestaan tyydyttää datatieteilijöiden ja ML-mallien tavoitetta epävarmuuden vähentämiseksi.”
Mitä on informaatiovoitto?
Käsitteellä entropia on tärkeä rooli informaatiovoiton laskemisessa.
Informaatiovoittoa sovelletaan kvantifioimaan sitä, mikä piirre tarjoaa maksimaalisen informaation luokittelusta perustuen entropian käsitteeseen, ts. kvantifioimalla epävarmuuden, epäjärjestyksen tai epäpuhtauden suuruus yleensä siten, että pyritään vähentämään ylhäältä (juurisolmusta) alhaalle (lehtisolmusta) lähtevän entropian määrää.
Informaatiovoitto otetaan luokan todennäköisyyksien tulona log, jolla on perusta 2 kyseisen luokan todennäköisyydestä, Entropian kaava on esitetty alla:
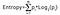
Tässä ”p” tarkoittaa todennäköisyyttä, että se on entropian funktio.
Gini-indeksi toiminnassa
Gini-indeksi, joka tunnetaan myös nimellä Gini-epäterävyys, laskee, kuinka suurella todennäköisyydellä tietty ominaisuus luokitellaan väärin, kun se valitaan satunnaisesti. Jos kaikki elementit liittyvät yhteen luokkaan, sitä voidaan kutsua puhtaaksi.
Hahmottakaamme Gini-indeksin kriteeri, kuten entropian ominaisuudet, Gini-indeksi vaihtelee arvojen 0 ja 1 välillä, jossa 0 ilmaisee luokittelun puhtautta, eli kaikki elementit kuuluvat tiettyyn luokkaan tai siellä on vain yksi luokka. Ja 1 ilmaisee elementtien satunnaista jakautumista eri luokkiin. Gini-indeksin arvo 0,5 osoittaa, että elementit jakautuvat tasaisesti joihinkin luokkiin.
Päätöksentekopuuta suunniteltaessa suositaan piirteitä, joilla on pienin Gini-indeksin arvo. Voit oppia toisen puuhun perustuvan algoritmin (Random Forest).
Gini-indeksi määritetään vähentämällä kunkin luokan todennäköisyyksien neliösumma yhdestä, matemaattisesti Gini-indeksi voidaan ilmaista seuraavasti:
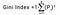
Jossa Pi tarkoittaa todennäköisyyttä, jolla alkio luokitellaan tiettyyn luokkaan.
Classification and Regression Tree (CART) -algoritmi käyttää Gini-indeksin menetelmää binäärijakojen synnyttämiseen.
Lisäksi päätöspualgoritmit hyödyntävät informaatiovoittoa solmun jakamiseen ja Gini-indeksi tai entropia on informaatiovoiton punnitsemiseen käytettävä väylä.
Gini-indeksi vs. Information Gain
Katsokaa alla saada eroavaisuutta Gini-indeksin ja Information Gainin välillä,
- Gini-indeksi helpottaa isompia jakaumia niin helppo toteuttaa, kun taas Information Gain suosii pienempiä jakaumia, joilla on pieni määrä useita erityisiä arvoja.
- Gini-indeksin menetelmää käytetään CART-algoritmeissa, sen sijaan Information Gainia käytetään ID3-, C4.5-algoritmeissa.
- Gini-indeksi toimii kategoristen kohdemuuttujien suhteen ”onnistumisen” tai ”epäonnistumisen” suhteen ja suorittaa vain binäärisen jaon, päinvastoin Information Gain laskee erotuksen entropian välillä ennen ja jälkeen jaon ja ilmaisee epäpuhtauden luokkien elementeissä.
Johtopäätökset
Gini-indeksiä ja Information Gainia käytetään reaaliaikaisen skenaarion analyysiin, ja dataa, joka on todellista ja joka kaapattiin reaaliaikaisesta analyysistä. Lukuisissa määritelmissä se on mainittu myös nimellä ”datan epäpuhtaus” tai ” miten data jakautuu. Voimme siis laskea, mitkä tiedot ottavat vähemmän tai enemmän osaa päätöksentekoon.
Tänään päädyn huippulukemiin:
- Mikä on OpenAI GPT-3?
- Reliance Jio ja JioMart:
- 6 Major Branches of Artificial Intelligence(AI).
- Top 10 Big Data -teknologiaa vuonna 2020
- Miten analytiikka muuttaa hotelli- ja ravintola-alaa
Hienoa, olet päässyt tämän blogin loppuun asti! Kiitos lukemisesta!!!!!