
TLDR: Indeksointi on vain tapa ryhmitellä dokumentteja, jakaa kokoelmat ryhmiin suorituskyvyn nopeuttamiseksi
Yleiskatsaus
Indeksit lisäävät kyselyn suorituskykyä sekä sitä käytetään hakuihin
Ajatus indeksoinnista MongoDB:ssä on samankaltainen kuin minkä tahansa kirjan hakemisto, Ne lisäävät nopeutta sivujen löytämiseen. Indeksi MongoDB:ssä lisää dokumenttien löytämisen nopeutta
Miten indeksit toimivat?
Aluksi ymmärretään, miten indeksi ilmoitetaan MongoDB:ssä
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Tässä kenttä on ”fieldName”, joka indeksoidaan. ”Value” voi olla -1 tai 1 tai ”text”.
Se määrittelee indeksin tyypin, 1 tai -1 lisää find()-kyselyn suorituskykyä kun taas ”text” käytetään hakuun.
1 ja -1 antavat indeksin järjestyksen. Ascending = -1 & Descending =1
Nyt, Miten indeksit toimivat konepellin alla?
Kuvittele kokoelma käyttäjiä, joista jokainen dokumentti sisältää erilaisia tietoja, joista yksi on pistemäärä.
Esitettäköön, että haluamme kaikkien käyttäjien pistemääräksi 23.
Kun indeksiä ei ole olemassa, MongoDB käy jokaisen dokumentin läpi löytääkseen kysytyn dokumentin, Tätä kutsutaan Collection scaniksi, MongoDB:llä on tälle lyhenne COLLSCAN (Tätä kutsutaan Table scaniksi relaatiotietokannoissa)
Miten voimme optimoida tämän?
Taulukon optimoimiseksi voimme luoda taulukon, jossa on yksi sarake pisteytykselle ja toinen sarake viitteille, joka sisältää dokumenttien ID:t, joilla on kyseinen pisteytys. Nyt meidän tarvitsee skannata vain tämä taulukko sen sijaan, että skannaisimme koko tietokannan. Tämä on paljon nopeampaa. Juuri tämä on indeksi.
Indeksit auttavat MongoDB:tä rajaamaan skannattavan tietokokonaisuuden. Tätä kutsutaan indeksiskannaukseksi, MongoDB:llä on tällekin lyhenne IXNSCAN
Tässä on visuaalinen esitys pisteet indeksistä ja sen kartoituksesta.
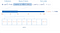
Indexin avulla saavutettava suorituskykyparannus on näkyvissä vasta, kun dokumenttien määrä ylittää noin 100K.
Voit itse verrata sitä vertaamalla kahta kyselyä toinen indeksoidulla kentällä ja toinen ilman indeksiä
db.<collection name>.find(query).explain()
Palautetaan
objekti.winingPlan.stage kertoo skannauksen tyypin COLLSCAN tai IXNSCAN
mutta se ei kerro suoritukseen kulunutta aikaa
käytä explain(’executionStat’) metodia ennen kyselymetodia kuten find
.
db.<collection name>explain('executionStat').find(query)

executionTimeMillis kertoo suoritukseen kuluneen ajan
Indeksin haittapuolia
Indeksit eivät ole ilmaisia, Indeksit maksavat tilaa. Indeksit voivat lisätä lukunopeutta, mutta aina kun jotain kirjoitetaan, indeksi on päivitettävä tämän ratkaisemiseksi käytämme B-puuta teemme joitakin laskutoimituksia ennen lisäystä, jotta se on nopeampi.
B-puu
Indeksit eivät ole ryhmätaulukko, käsitteellisesti se on itse asiassa B-puu (Binary Tree) ei vain MongoDB, myös SQL-tietokanta käyttää B-puuta indeksointiin
Tämä video selittää parhaiten B-puun