
TLDR : L’indexation est juste une façon de regrouper des documents, de diviser des collections en groupes pour accélérer les performances
Overview
Les index augmentent les performances des requêtes ainsi qu’il est utilisé pour les recherches
L’idée de l’indexation dans MongoDB est similaire à l’index de n’importe quel livre, Ils augmentent la vitesse de trouver une page. L’index dans MongoDB augmente la vitesse de recherche des documents
Comment fonctionnent les index ?
D’abord, comprenons comment vous déclarez l’index dans MongoDB
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Ici le champ est le « fieldName » qui sera indexé. « Value » pourrait être -1 ou 1 ou « text ».
Il définit le type d’index, 1 ou -1 augmente les performances de la requête find() alors que « text » est utilisé pour la recherche.
1 et -1 donnent l’ordre de l’index. Ascendant = -1 & Descendant =1
Maintenant, comment les index fonctionnent sous le capot ?
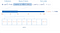
Imaginez une collection d’utilisateurs, chaque document contenant diverses informations, l’une d’entre elles étant le score.
Disons que nous voulons que tous les utilisateurs aient un score de 23.
Lorsqu’il n’y a pas d’index, MongoDB parcourt chaque document pour trouver le document interrogé, Cela s’appelle le balayage de collection, MongoDB a un raccourci pour ce COLLSCAN (Cela s’appelle le balayage de table dans les bases de données relationnelles)
Comment pouvons-nous optimiser cela ?
Pour optimiser cela, nous pouvons créer une table avec une colonne pour le score et une autre colonne pour les références qui contiendra les ID des documents avec ce score particulier. Maintenant, nous avons seulement besoin de scanner cette table plutôt que de scanner toute la base de données. C’est beaucoup plus rapide. C’est exactement ce qu’est un index.
Les index aident MongoDB à réduire le jeu de données qu’il devra scanner. Ceci est appelé Index Scan, MongoDB a un raccourci pour cela aussi IXNSCAN
Voici une représentation visuelle d’un Index de score et de son mapping.
L’amélioration des performances par l’Index n’est visible que lorsque le nombre de documents franchit 100K environ.
Vous pouvez le faire vous-même en comparant deux requêtes une avec un champ indexé et une sans Index
db.<collection name>.find(query).explain()
Un Objet sera retourné
objet.winingPlan.stage vous indiquera le type de scan COLLSCAN ou IXNSCAN
mais il ne vous indiquera pas le temps pris dans l’exécution
utiliser la méthode explain(‘executionStat’) avant la méthode de requête comme find
.
db.<collection name>explain('executionStat').find(query)

executionTimeMillis vous indiquera le temps pris dans l’exécution
Avantages de l’index
Les index ne sont pas gratuits, Les index coûtent de l’espace. Les index peuvent augmenter la vitesse de lecture mais à chaque fois que quelque chose est écrit, l’index doit être mis à jour pour résoudre cela nous utilisons le B- tree nous faisons quelques calculs avant l’insertion pour que ce soit plus rapide.
B-Tree
Les index ne sont pas une Table de groupes, conceptuellement c’est en fait un B-Tree (Binary Tree) pas seulement MongoDB, la base de données SQL utilise aussi le B Tree pour l’indexation
cette Vidéo explique le mieux le B Tree
.