

En commençant par le Data mining, une approche unique nouvellement raffinée à adopter avec succès dans la prédiction des données, c’est une méthode propice utilisée pour l’analyse des données pour découvrir des tendances et des connexions dans les données qui pourraient jeter une véritable interférence.
Certains outils populaires exploités dans l’exploration de données sont les réseaux neuronaux artificiels(ANN), la régression logistique, l’analyse discriminante et les arbres de décision.
L’arbre de décision est l’outil le plus notoire et le plus puissant qui est facile à comprendre et rapide à mettre en œuvre pour la découverte de connaissances à partir d’ensembles de données énormes et complexes.
Introduction
Le nombre de théoriciens et de praticiens repolissent régulièrement les techniques afin de rendre le processus plus rigoureux, adéquat et rentable.
Initialement, les arbres de décision sont utilisés dans la théorie de la décision et les statistiques à grande échelle. Ce sont également des outils convaincants dans l’exploration de données, la recherche d’informations, l’exploration de textes et la reconnaissance des formes dans l’apprentissage automatique.
Ici, je recommanderais de lire mon article précédent pour s’attarder et aiguiser votre pool de connaissances en termes d’arbres de décision.
L’essence des arbres de décision prévaut dans la division des ensembles de données dans ses sections qui émergent indirectement un arbre de décision (inversé) ayant des nœuds de racines au sommet. Le modèle stratifié de l’arbre de décision conduit au résultat final à travers les nœuds de passage des arbres.
Ici, chaque nœud comprend un attribut (caractéristique) qui devient la cause racine de la division supplémentaire dans la direction descendante.
Pouvez-vous répondre,
- Comment décider quelle caractéristique doit être située au nœud racine,
- La caractéristique la plus précise pour servir de nœuds internes ou de nœuds feuilles,
- Comment diviser l’arbre,
- Comment mesurer la précision du fractionnement de l’arbre et bien d’autres choses encore.
Il existe quelques paramètres fondamentaux de fractionnement pour répondre aux problèmes considérables discutés ci-dessus. Et oui, dans le royaume de cet article, nous couvrirons l’Entropie, l’indice de Gini, le gain d’information et leur rôle dans l’exécution de la technique des arbres de décision.
Pendant le processus de prise de décision, de multiples caractéristiques participent et il devient essentiel de se préoccuper de la pertinence et des conséquences de chaque caractéristique assignant ainsi la caractéristique appropriée au nœud racine et traversant le fractionnement des nœuds vers le bas.
S’orienter vers la direction descendante conduit à des diminutions du niveau d’impureté et d’incertitude et donne lieu à une meilleure classification ou à un fractionnement d’élite à chaque nœud.
Pour résoudre la même chose, des mesures de fractionnement sont utilisées comme l’entropie, le gain d’information, l’indice de Gini, etc.
Définir l’entropie
« Qu’est-ce que l’entropie ? » Selon les mots de Lyman, ce n’est rien que la mesure du désordre, ou la mesure de la pureté. En gros, c’est la mesure de l’impureté ou du caractère aléatoire des points de données.
Un ordre élevé de désordre signifie un faible niveau d’impureté, laissez-moi simplifier. L’entropie est calculée entre 0 et 1, bien que selon le nombre de groupes ou de classes présents dans l’ensemble de données, elle pourrait être supérieure à 1 mais elle signifie la même signification, c’est-à-dire un niveau de désordre plus élevé.
Pour une interprétation simple, confinons la valeur de l’entropie entre 0 et 1.
Dans l’image ci-dessous, une forme de « U » inversé représente la variation de l’entropie sur le graphique, l’axe des x présente les points de données et l’axe des y montre la valeur de l’entropie. L’entropie est la plus faible (pas de désordre) aux extrêmes (les deux extrémités) et maximale (désordre élevé) au milieu du graphique.

« L’entropie est un degré d’aléatoire ou d’incertitude, à son tour, satisfait la cible des scientifiques de données et des modèles ML pour réduire l’incertitude. »
Qu’est-ce que le gain d’information ?
Le concept d’entropie joue un rôle important dans le calcul du gain d’information.
Le gain d’information est appliqué pour quantifier quelle caractéristique fournit une information maximale sur la classification basée sur la notion d’entropie, c’est-à-dire. en quantifiant la taille de l’incertitude, du désordre ou de l’impureté, en général, avec l’intention de diminuer la quantité d’entropie initiant du haut (nœud racine) vers le bas(nœuds feuilles).
Le gain d’information prend le produit des probabilités de la classe avec un logarithme ayant pour base 2 cette probabilité de classe, la formule de l’entropie est donnée ci-dessous :
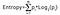
Ici « p » désigne la probabilité qu’elle est fonction de l’entropie.
L’indice de Gini en action
L’indice de Gini, également connu sous le nom d’impureté de Gini, calcule la quantité de probabilité qu’un élément spécifique soit classé de manière incorrecte lorsqu’il est sélectionné au hasard. Si tous les éléments sont liés à une seule classe alors elle peut être qualifiée de pure.
Persuivons le critère de l’indice de Gini, comme les propriétés de l’entropie, l’indice de Gini varie entre les valeurs 0 et 1, où 0 exprime la pureté de la classification, c’est-à-dire que tous les éléments appartiennent à une classe spécifiée ou qu’une seule classe y existe. Et 1 indique la répartition aléatoire des éléments entre les différentes classes. La valeur de 0,5 de l’indice de Gini montre une distribution égale des éléments sur certaines classes.
Lors de la conception de l’arbre de décision, les caractéristiques possédant la plus petite valeur de l’indice de Gini seraient privilégiées. Vous pouvez apprendre un autre algorithme basé sur les arbres(Random Forest).
L’indice de Gini est déterminé en déduisant la somme des carrés des probabilités de chaque classe de l’une, mathématiquement, l’indice de Gini peut être exprimé comme:
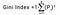
Où Pi désigne la probabilité qu’un élément soit classé pour une classe distincte.
L’algorithme CART (Classification and Regression Tree) déploie la méthode de l’indice de Gini pour être à l’origine de divisions binaires.
En outre, les algorithmes d’arbres de décision exploitent le gain d’information pour diviser un nœud et l’indice de Gini ou l’entropie est le passage pour pondérer le gain d’information.
Indice de Gini vs Gain d’information
Regardez ci-dessous pour obtenir la divergence entre l’indice de Gini et le Gain d’information,
- L’indice de Gini facilite les plus grandes distributions si faciles à mettre en œuvre alors que le Gain d’information favorise les distributions moindres ayant un petit compte avec de multiples valeurs spécifiques.
- La méthode de l’indice de Gini est utilisée par les algorithmes CART, contrairement à elle, le gain d’information est utilisé dans les algorithmes ID3, C4.5.
- L’indice de Gini opère sur les variables cibles catégorielles en termes de « succès » ou d' »échec » et n’effectue qu’une division binaire, à l’opposé de cela, le Gain d’information calcule la différence entre l’entropie avant et après la division et indique l’impureté dans les classes d’éléments.
Conclusion
L’indice de Gini et le Gain d’information sont utilisés pour l’analyse du scénario en temps réel, et les données sont réelles qui sont capturées à partir de l’analyse en temps réel. Dans de nombreuses définitions, il a également été mentionné comme » impureté des données » ou » comment les données sont distribuées « . Ainsi, nous pouvons calculer quelles données prennent moins ou plus de part dans la prise de décision.
Aujourd’hui, je finis avec nos lectures principales:
- Qu’est-ce que OpenAI GPT-3?
- Reliance Jio et JioMart : Stratégie marketing, analyse SWOT et écosystème de travail.
- 6 grandes branches de l’intelligence artificielle(IA).
- Top 10 Big Data Technologies in 2020
- Comment l’analytique transforme l’industrie hôtelière
Oh super, vous êtes arrivé à la fin de ce blog ! Merci de votre lecture!!!!!