
Il est recommandé de comprendre ce qu’est un réseau neuronal avant de lire cet article. Dans le processus de construction d’un réseau neuronal, l’un des choix que vous avez à faire est de savoir quelle fonction d’activation utiliser dans la couche cachée ainsi que dans la couche de sortie du réseau. Cet article aborde certains de ces choix.
Éléments d’un réseau neuronal :-
Couche d’entrée :- Cette couche accepte les caractéristiques d’entrée. Elle fournit des informations du monde extérieur au réseau, aucun calcul n’est effectué à cette couche, les nœuds ici ne font que transmettre les informations (caractéristiques) à la couche cachée.
Couche cachée :- Les nœuds de cette couche ne sont pas exposés au monde extérieur, ils sont la partie de l’abstraction fournie par tout réseau neuronal. La couche cachée effectue toutes sortes de calculs sur les caractéristiques entrées par la couche d’entrée et transfère le résultat à la couche de sortie.
Couche de sortie :- Cette couche fait remonter les informations apprises par le réseau vers le monde extérieur.
Qu’est-ce qu’une fonction d’activation et pourquoi les utiliser ?
Définition de la fonction d’activation :- La fonction d’activation décide, si un neurone doit être activé ou non en calculant la somme pondérée et en ajoutant en outre un biais avec celle-ci. Le but de la fonction d’activation est d’introduire une non-linéarité dans la sortie d’un neurone.
Explication :-
Nous savons, le réseau neuronal a des neurones qui fonctionnent en correspondance du poids, du biais et de leur fonction d’activation respective. Dans un réseau neuronal, nous mettons à jour les poids et les biais des neurones sur la base de l’erreur à la sortie. Ce processus est connu sous le nom de rétropropagation. Les fonctions d’activation rendent la rétropropagation possible puisque les gradients sont fournis avec l’erreur pour mettre à jour les poids et les biais.
Pourquoi avons-nous besoin de fonctions d’activation non linéaires :-
Un réseau neuronal sans fonction d’activation est essentiellement juste un modèle de régression linéaire. La fonction d’activation effectue la transformation non linéaire de l’entrée, ce qui le rend capable d’apprendre et d’effectuer des tâches plus complexes.
Preuve mathématique :-
Supposons que nous ayons un réseau neuronal comme celui-ci :-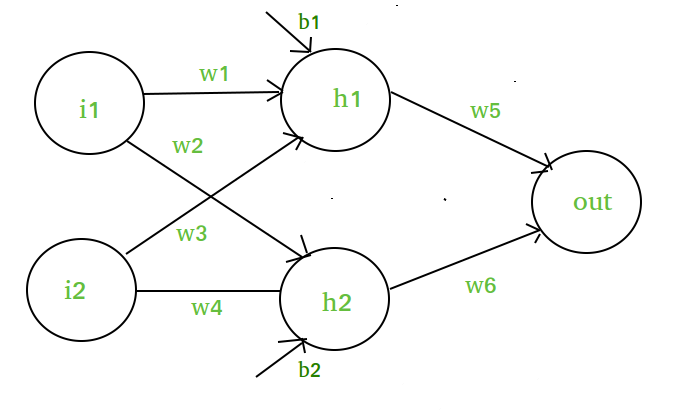
Éléments du diagramme :-
Couche cachée, c’est-à-dire . couche 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Ici,
- z(1) est la sortie vectorisée de la couche 1
- W(1) sont les poids vectorisés attribués aux neurones
de la couche cachée c’est-à-dire.e. w1, w2, w3 et w4- X sont les caractéristiques d’entrée vectorisées, c’est à dire i1 et i2
- b est le biais vectorisé assigné aux neurones de la couche
cachée, c’est-à-dire b1 et b2- a(1) est la forme vectorisée de toute fonction linéaire.
(Note : Nous ne considérons pas la fonction d’activation ici)
Couche 2, c’est à dire couche de sortie :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Calcul à la couche de sortie :
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Cette observation aboutit à nouveau à une fonction linéaire même après avoir appliqué une couche cachée, donc nous pouvons conclure que, peu importe le nombre de couches cachées que nous attachons dans le réseau neuronal, toutes les couches se comporteront de la même manière parce que la composition de deux fonctions linéaires est une fonction linéaire elle-même. Un neurone ne peut pas apprendre avec une simple fonction linéaire qui lui est attachée. Une fonction d’activation non linéaire le laissera apprendre selon la différence par rapport à l’erreur.
C’est pourquoi nous avons besoin d’une fonction d’activation.
VARIANTS DE FONCTION D’ACTIVATION :-
1). Fonction linéaire :-
- Equation : La fonction linéaire a l’équation similaire à celle d’une ligne droite c’est-à-dire y = ax
- Qu’importe le nombre de couches que nous avons, si toutes sont de nature linéaire, la fonction d’activation finale de la dernière couche n’est rien d’autre qu’une simple fonction linéaire de l’entrée de la première couche.
- Plage : -inf à +inf
- Utilisations : La fonction d’activation linéaire est utilisée à un seul endroit c’est-à-dire la couche de sortie.La fonction d’activation linéaire est utilisée à un seul endroit, c’est-à-dire dans la couche de sortie.
- Problèmes : Si nous différencions la fonction linéaire pour apporter la non-linéarité, le résultat ne dépendra plus de l’entrée « x » et la fonction deviendra constante, cela n’introduira pas de comportement révolutionnaire dans notre algorithme.
Par exemple : Le calcul du prix d’une maison est un problème de régression. Le prix de la maison peut avoir n’importe quelle valeur grande/petite, donc nous pouvons appliquer une activation linéaire à la couche de sortie. Même dans ce cas, le réseau neuronal doit avoir une fonction non linéaire quelconque au niveau des couches cachées.
2). Fonction Sigmoïde :-
- C’est une fonction qui est tracée comme un graphique en forme de ‘S’.
- Equation :
A = 1/(1 + e-x) - Nature : non linéaire. Remarquez que les valeurs de X se situent entre -2 et 2, les valeurs de Y sont très raides. Cela signifie que de petits changements dans x entraîneraient également de grands changements dans la valeur de Y.
- Plage de valeurs : 0 à 1
- Utilisations : Habituellement utilisé dans la couche de sortie d’une classification binaire, où le résultat est soit 0 ou 1, car la valeur de la fonction sigmoïde se situe entre 0 et 1 seulement donc, le résultat peut être prédit facilement pour être 1 si la valeur est supérieure à 0,5 et 0 sinon.
3). Fonction Tanh :- L’activation qui fonctionne presque toujours mieux que la fonction sigmoïde est la fonction Tanh également connue sous le nom de fonction tangente hyperbolique. C’est en fait une version mathématiquement décalée de la fonction sigmoïde. Les deux sont similaires et peuvent être dérivées l’une de l’autre.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Plage de valeurs :- -1 à +1
- Nature :- non linéaire
- Utilisations :- Généralement utilisée dans les couches cachées d’un réseau neuronal car ses valeurs se situent entre -1 et 1 donc la moyenne pour la couche cachée sort être 0 ou très proche de celle-ci, donc aide à centrer les données en amenant la moyenne proche de 0. Cela rend l’apprentissage de la couche suivante beaucoup plus facile.
- Equation :- A(x) = max(0,x). Elle donne une sortie x si x est positif et 0 sinon.
- Plage de valeurs :- [0, inf)
- Nature :- non linéaire, ce qui signifie que nous pouvons facilement rétropropager les erreurs et avoir plusieurs couches de neurones activées par la fonction ReLU.
- Utilisations :- ReLu est moins coûteuse en calcul que tanh et sigmoïde car elle implique des opérations mathématiques plus simples. À un moment donné, seuls quelques neurones sont activés, ce qui rend le réseau clairsemé, ce qui le rend efficace et facile à calculer.
4). RELU :- Signifie unité linéaire rectifiée. C’est la fonction d’activation la plus utilisée. Principalement implémentée dans les couches cachées des réseaux neuronaux.
En termes simples, RELU apprend beaucoup plus rapidement que la fonction sigmoïde et Tanh.
5). Fonction softmax :- La fonction softmax est également un type de fonction sigmoïde mais elle est pratique lorsque nous essayons de traiter des problèmes de classification.
- Nature :- non linéaire
- Utilisations :- Généralement utilisée lorsqu’on essaie de traiter plusieurs classes. La fonction softmax écraserait les sorties pour chaque classe entre 0 et 1 et diviserait également par la somme des sorties.
- Sortie :- La fonction softmax est idéalement utilisée dans la couche de sortie du classificateur où nous essayons effectivement d’atteindre les probabilités pour définir la classe de chaque entrée.
- La règle de base est que si vous ne savez vraiment pas quelle fonction d’activation utiliser, alors utilisez simplement RELU car c’est une fonction d’activation générale et elle est utilisée dans la plupart des cas de nos jours.
- Si votre sortie est pour la classification binaire alors, la fonction sigmoïde est un choix très naturel pour la couche de sortie.
CHOISIR LA BONNE FONCTION D’ACTIVATION
Foot Note :-
La fonction d’activation fait la transformation non linéaire à l’entrée le rendant capable d’apprendre et d’effectuer des tâches plus complexes.