
Det rekommenderas att du förstår vad ett neuralt nätverk är innan du läser den här artikeln. I Processen att bygga ett neuralt nätverk är ett av de val du får göra vilket aktiveringsfunktion du ska använda i det dolda lagret samt i nätverkets utgångslager. I den här artikeln diskuteras några av valen.
Element i ett neuralt nätverk :-
Inputlager :- Det här lagret tar emot inputfunktioner. Det ger information från omvärlden till nätverket, ingen beräkning utförs i det här lagret, noderna här skickar bara informationen (funktioner) vidare till det dolda lagret.
Dolt lager :- Noderna i det här lagret är inte exponerade för omvärlden, de är en del av den abstraktion som tillhandahålls av ett neuralt nätverk. Det dolda lagret utför alla typer av beräkningar på de funktioner som matas in via inmatningslagret och överför resultatet till utmatningslagret.
Utmatningslagret :- Det här lagret överför den information som nätverket har lärt sig till den yttre världen.
Vad är en aktiveringsfunktion och varför ska man använda dem?
Definition av aktiveringsfunktion:- Aktiveringsfunktionen bestämmer om en neuron ska aktiveras eller inte genom att beräkna den viktade summan och lägga till en förskjutning med den. Syftet med aktiveringsfunktionen är att införa icke-linjäritet i en neurons utgång.
Förklaring :-
Vi vet att neurala nätverk har neuroner som arbetar i korrespondens med vikt, bias och deras respektive aktiveringsfunktion. I ett neuralt nätverk skulle vi uppdatera neuronernas vikter och bias på grundval av felet vid utgången. Denna process är känd som back-propagation. Aktiveringsfunktioner gör back-propagation möjlig eftersom gradienterna levereras tillsammans med felet för att uppdatera vikter och bias.
Varför behöver vi icke-linjära aktiveringsfunktioner :-
Ett neuralt nätverk utan aktiveringsfunktion är i princip bara en linjär regressionsmodell. Aktiveringsfunktionen gör den icke-linjära omvandlingen av indata vilket gör att det kan lära sig och utföra mer komplexa uppgifter.
Matematiska bevis :-
Antag att vi har ett neuralt nät som detta :-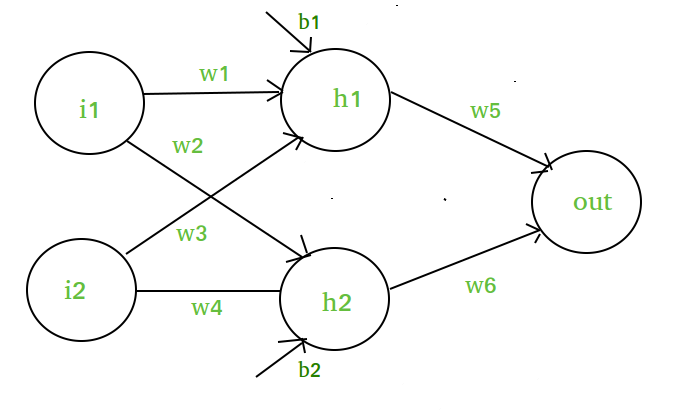
Diagrammets beståndsdelar :-
Det dolda lagret, dvs. Skikt 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Här är
- z(1) den vektoriserade utgången av skikt 1
- W(1) de vektoriserade vikter som tilldelats neuronerna
i det dolda lagret i.e. w1, w2, w3 och w4- X är de vektoriserade inmatningsfunktionerna, dvs. i1 och i2
- b är den vektoriserade bias som tilldelas neuronerna i det dolda
lagret, dvs. b1 och b2- a(1) är den vektoriserade formen av en linjär funktion.
(Observera: Vi tar inte hänsyn till aktiveringsfunktionen här)
Lag 2, dvs. Utgångslager :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Beräkning i utgångslager:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Denna observation resulterar återigen i en linjär funktion även efter att ha tillämpat ett dolt lager, och därför kan vi dra slutsatsen att det inte spelar någon roll hur många dolda lager vi lägger till i det neurala nätet, alla lager kommer att bete sig likadant, eftersom sammansättningen av två linjära funktioner i sig självt är en linjär funktion. Neuronerna kan inte lära sig med bara en linjär funktion kopplad till dem. En icke-linjär aktiveringsfunktion låter den lära sig enligt skillnaden i förhållande till felet.
Därför behöver vi en aktiveringsfunktion.
VARIANTER AV AKTIVATIONSFUNKTIONER:-
1). Linjär funktion :-
- Ekvation : Linjär funktion har en ekvation som liknar den för en rak linje, dvs. y = ax
- Oavsett hur många lager vi har, om alla är linjära till sin natur, är den slutliga aktiveringsfunktionen för det sista lagret inget annat än bara en linjär funktion av indata från det första lagret.
- Intervall : -inf till +inf
- Användningsområden : Linjär aktiveringsfunktion används endast på ett ställe, dvs.
- Problem: Om vi differentierar den linjära funktionen så att den blir icke-linjär, kommer resultatet inte längre att vara beroende av ingången ”x” och funktionen kommer att bli konstant, vilket inte kommer att leda till något banbrytande beteende för vår algoritm.
Till exempel: Beräkning av priset på ett hus är ett regressionsproblem. Huspriset kan ha vilket stort eller litet värde som helst, så vi kan tillämpa linjär aktivering i utgångsskiktet. Även i detta fall måste det neurala nätet ha en icke-linjär funktion i de dolda lagren.
2). Sigmoidfunktion :-
- Det är en funktion som plottas som en S-formad graf.
- Ekvation :
A = 1/(1 + e-x) - Natur : Icke linjär. Notera att X-värdena ligger mellan -2 och 2, Y-värdena är mycket branta. Detta innebär att små förändringar i x också skulle medföra stora förändringar i värdet på Y.
- Värdeområde : 0 till 1
- Användning : Används vanligen i utgångsskiktet i en binär klassificering, där resultatet är antingen 0 eller 1, eftersom värdet för den sigmoida funktionen endast ligger mellan 0 och 1, så resultatet kan lätt förutsägas bli 1 om värdet är större än 0,5 och 0 i annat fall.
3). Tanh-funktionen :- Den aktivering som nästan alltid fungerar bättre än sigmoidfunktionen är Tanh-funktionen som också kallas tangent hyperbolisk funktion. Det är faktiskt en matematiskt förskjuten version av sigmoidfunktionen. Båda liknar varandra och kan härledas från varandra.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Värdeområde :- -1 till +1
- Karaktär :- Icke-linjär
- Användningsområden :- Används vanligtvis i de dolda skikten i ett neuronalt nätverk, eftersom dess värden ligger mellan -1 och 1 och medelvärdet för det dolda skiktet därmed är 0 eller mycket nära 0. Detta hjälper till att centrera data genom att föra medelvärdet nära 0. Detta gör inlärningen av nästa lager mycket lättare.
- Ekvation :- A(x) = max(0,x). Den ger en utgång x om x är positiv och 0 annars.
- Värdeområde :- [0, inf)
- Karaktär :- Icke-linjär, vilket innebär att vi lätt kan backpropagera felen och ha flera lager av neuroner som aktiveras av ReLU-funktionen.
- Användningsområden :- ReLu är mindre beräkningskostnadskrävande än tanh och sigmoid, eftersom den omfattar enklare matematiska operationer. Vid ett tillfälle aktiveras endast ett fåtal neuroner vilket gör nätverket gles vilket gör det effektivt och lätt att beräkna.
4). RELU :- Står för Rektifierad linjär enhet. Det är den mest använda aktiveringsfunktionen. Huvudsakligen implementerad i dolda lager i neurala nätverk.
Med enkla ord lär sig RELU mycket snabbare än sigmoid- och tanh-funktionen.
5). Softmax-funktion :- Softmax-funktionen är också en typ av sigmoidfunktion men är praktisk när vi försöker hantera klassificeringsproblem.
- Natur :- icke-linjär
- Användningsområden :- Används vanligen när vi försöker hantera flera klasser. Softmax-funktionen skulle klämma utgångarna för varje klass mellan 0 och 1 och även dividera med summan av utgångarna.
- Utgång :- Softmax-funktionen används helst i klassificerarens utgångslager där vi faktiskt försöker uppnå sannolikheterna för att definiera klassen för varje ingång.
- Den grundläggande tumregeln är att om du verkligen inte vet vilken aktiveringsfunktion du ska använda, använd då helt enkelt RELU eftersom det är en allmän aktiveringsfunktion och används i de flesta fall nuförtiden.
- Om din utgång är för binär klassificering är sigmoidfunktionen ett mycket naturligt val för utgångsskiktet.
HAN LÖSAR RÄTT AKTIVATIONSFUNKTION
Fotnot :-
Aktiveringsfunktionen gör den icke-linjära omvandlingen av inmatningen vilket gör att den kan lära sig och utföra mer komplexa uppgifter.