

データマイニングから始まり、データ予測にうまく採用されるように新たに洗練されたワンサイズ フィットのアプローチ、それは本物の干渉をキャストするかもしれないデータの傾向や接続を発見するためにデータ分析に使用される有望な方法である。
データマイニングで使用される一般的なツールには、人工ニューラルネットワーク(ANN)、ロジスティック回帰、判別分析、決定木などがあります。
決定木は、巨大で複雑なデータセットからの知識発見において、理解しやすく迅速に実装できる最も有名で強力なツールです。
はじめに
多くの理論家と実務家は、プロセスをより厳密で適切かつ費用対効果の高いものにするために、定期的に技術を磨き直しています。
当初、決定木は決定論と統計で大規模に使用されています。 これらはまた、データマイニング、情報検索、テキストマイニング、および機械学習におけるパターン認識における説得力のあるツールです。
ここで、私は、決定木の観点からあなたの知識プールを滞りなく、シャープにするために私の以前の記事を読むことをお勧めします。 決定木の層別モデルは、木のノードを通過することで最終結果を導く。
ここで、各ノードは、下方向にさらに分割する根本原因となる属性(特徴)から構成される。
- どの特徴をルートノードに置くか決める方法、
- 内部ノードや葉ノードとして機能する最も正確な特徴、
- 木の分割方法、
- 木の分割の精度を測る方法、その他多数、答えていただけますか?
上で述べたかなりの問題に対処するために、いくつかの基本的な分割パラメータがあります。 この記事の領域では、エントロピー、ジニ指数、情報利得、および決定木技術の実行におけるそれらの役割を取り上げます。
意思決定のプロセスでは、複数の特徴が参加し、各特徴の関連性と結果を考慮することが不可欠になるため、ルート ノードに適切な特徴を割り当て、ノードの分割を下向きにトラバースします。
下方への移動は、不純物と不確実性のレベルの減少につながり、各ノードでより良い分類またはエリート分割をもたらす。
これを解決するために、エントロピー、情報利得、ジニ指数などの分割尺度が使用される。 ライマンの言葉を借りれば、それは単なる無秩序の尺度、あるいは純粋さの尺度ではありません。 基本的には、データ点の不純度またはランダム性の測定です。
高次の無秩序は、不純度が低いことを意味しますが、簡単に説明しましょう。 エントロピーは0と1の間で計算されるが、データセットに存在するグループまたはクラスの数によっては1より大きくなることもあるが、同じ意味、つまり無秩序のレベルが高いことを意味する。
解釈を簡単にするために、エントロピーの値を 0 と 1 の間に限定してみましょう。
下の画像では、グラフ上のエントロピーの変化を逆「U」字型で表しており、X 軸はデータ点、Y 軸はエントロピーの値を示しています。 グラフの両端ではエントロピーが最も小さく(無秩序)、中央ではエントロピーが最大(高秩序)となっています。

“Entropy is a degree of randomness or uncertainty, turn, satisfied of data Scientists and ML models to reduce uncertainty. “エントロピーは、ランダム性または不確実性の程度である。”
情報利得とは何か?
情報利得の計算には、エントロピーの概念が重要な役割を果たす。
情報利得は、エントロピーの概念に基づいて分類に関する最大の情報、すなわち、どの特徴を提供するかを定量化するために適用される。 一般に、トップ(ルートノード)からボトム(リーフノード)へと始まるエントロピーの量を減少させることを意図して、不確実性、無秩序または不純物の大きさを定量化することによって、情報利得を適用する。
情報利得はクラスの確率とそのクラスの確率の底2を持つ対数の積をとり、エントロピーの式は以下に与えられる:
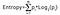
ここでpはそれがエントロピーの関数であるという確率を示している。
ジニ指数の動作
ジニ指数はジニ不純物とも呼ばれ、ランダムに選択したときに、特定の特徴が誤って分類される確率の大きさを計算するものである。 すべての要素が単一のクラスにリンクされている場合、それは純粋と呼ばれることができます。
ジニ指数の基準を知覚しましょう、エントロピーの特性のように、ジニ指数は値0と1の間で変化し、0は分類の純度を表す、すなわち、すべての要素が特定のクラスに属しているか、そこに一つのクラスしか存在しないことを意味します。 1は、様々なクラス間で要素がランダムに分布していることを示す。 ジニ指数の値が0.5であれば、いくつかのクラスにわたって要素が均等に分布していることを示す。
決定木を設計する際に、ジニ指数の値が最も小さい特徴が優先されることになる。 別の木ベースのアルゴリズム(Random Forest)を学ぶことができます。
ジニ指数は、各クラスの確率の二乗の合計を 1 から差し引くことによって決定され、数学的には次のように表されます:
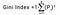
ここで Pi はある要素が異なるクラスに分類される確率を表します。
分類回帰木(CART)アルゴリズムは、バイナリ分割を生成するためにジニ指数の方法を展開する。
さらに、決定木アルゴリズムはノードを分割するために情報ゲインを利用し、ジニ指数またはエントロピーは情報ゲインを計量する通路となる。
Gini Index vs Information Gain
Gini Index と Information Gain の相違点について、以下を見てください。
- Gini Index は大きな分布を容易に実装でき、一方 Information Gain は小さなカウントで複数の特定の値を持つ小さな分布を優先します。
- ジニ指数はCARTアルゴリズムで使用され、それに対して情報利得はID3やC4.5アルゴリズムで使用されています。
- ジニ指数は、対象変数が「成功」か「失敗」かで分類され、2値分割のみを行うのに対し、情報利得は分割前後のエントロピーの差を計算し、要素のクラスにおける不純度を示す。 また、多くの定義で「データの不純物」や「データがどのように分布しているか」とも言及されている。
Today I end up with our top reads:
- What is OpenAI GPT-3?
- Reliance Jio and JioMart.All Rights Reserved: マーケティング戦略、SWOT分析、ワーキングエコシステム.
- 人工知能(AI)の6大分野.
- OpenAI GP-3とは?
- Top 10 Big Data Technologies in 2020
- How is the Analytics Transforming the Hospitality Industry
Oh great, you have made it to the end of this blog! お読みいただきありがとうございました!
。