
find は Linux でファイルを検索するための最も有名で強力なコマンドライン ユーティリティの 1 つであることは間違いありませんが、瞬時に結果が必要な状況では十分に高速ではないでしょう。 もし、コマンドラインからシステム上のファイルを検索したい場合、速度が最優先であれば、別のコマンドを使用することができます。 Locate.
このチュートリアルでは、わかりやすい例を使って、locateコマンドについて説明します。 ここで説明するすべての手順や例は、Ubuntu 16.04 LTS でテストされており、使用した locate のバージョンは 0.26 です。
How to use locate command in Linux
locateコマンドは非常に簡単に使用することができます。
locate
たとえば、’dir2′ という文字列を含むすべてのファイル名を検索したい場合、次のように locate を使用して検索できます:

注: ‘locate dir2’ (no asterisk) コマンドでも可能。
How locate command works, or why is it so fast
locate が非常に速い理由は、検索したファイルまたはディレクトリ名についてファイルシステムを読み込まないからです。 実際にデータベース (updatedb コマンドで準備) を参照して、ユーザーが探しているものを見つけ、その検索に基づいて、出力を生成します。 主な問題は、システム上に新しいファイルまたはディレクトリが作成されるたびに、正しく動作させるためにツールのデータベースを更新する必要があることです。
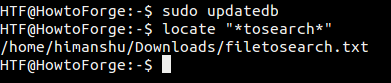
たとえば、システムの ‘Downloads’ ディレクトリにある ‘tosearch’ 文字列を含む名前のファイルを見つけようとすると、find コマンドは出力に 1 つの結果を生成します:

しかし、locate コマンドを使って同じ検索を行ってみると、出力は何も生成されない。
![]()
これは、ファイルがシステム上に作成された後、locate が検索するデータベースが更新されていないことを意味します。 そこで、データベースを更新してみましょう。これは、updatedbコマンドを使用して行うことができます。 その方法は次のとおりです。
sudo updatedb
そして、同じ locate コマンドを再度実行すると、出力にファイルが表示されます。
同様に、ファイルまたはディレクトリを削除した後、locate データベースが更新されていることを確認する必要があります。
How to make locate print the number or count of matching entries in the output
これまで見てきたように、locate コマンドはマッチしたファイルの名前とその完全パスまたは絶対パスを出力に表示する。 しかし、必要であれば、これらの情報をすべて削除し、代わりにマッチしたエントリの数またはカウントを表示するようにすることができる。 これは、-c コマンドライン オプションを使用して実行できます。

既存のファイルに対応するエントリのみを表示するよう locate を強制する方法
この記事の前半で既に説明したように、ファイルがシステムから削除されると、locate データベースを再び更新するまで、そのファイル名の出力が表示されつづけます。 しかし、この特定のケースでは、-e コマンド ライン オプションを使用して、データベースの更新をスキップし、正しい結果を出力することができます。 これは find コマンドで確認され、ファイルを検索できなくなりました:

しかし、locate を使用して同じ操作を実行すると、出力にまだファイルが表示されました:

その理由は、locate のデータベースがファイル削除後に更新されなかったからです。 しかし、-e オプションを使用するとうまくいきました。
![]()
このオプションについて、locate man ページに次のように書かれています。 “Print only entries that refer to files at the time locate is run.”
How to make locate ignore case distinction
デフォルトでは、locate コマンドが行う検索操作では大文字と小文字が区別されます。 しかし、-i コマンド ライン オプションを使用すると、大文字と小文字の区別を無視するように強制できます。
たとえば、私のシステム上に ‘newfiletosearch.txt’ と ‘NEWFILETOSEARCH.txt’ という 2 つのファイルがあったとします。 つまり、ご覧のとおり、ファイル名は同じですが、その大文字と小文字が異なるだけです。 たとえば、”*tosearch*” を検索するように locate に依頼した場合、小文字の名前だけが出力に表示されます。

How to separate output entries with ASCII NUL
デフォルトでは、locate コマンドが生成する出力項目は改行文字 (\n) で区切られています。 しかし、必要であれば、セパレータを変更し、改行文字の代わりにASCII NULを使用することができます。
たとえば、上記の最後のセクションで使用したのと同じコマンドを実行し、-0 コマンドライン・オプションを追加してみました:

すると、改行区切り文字はもはや存在せず、NUL に置き換えられていることがわかります。
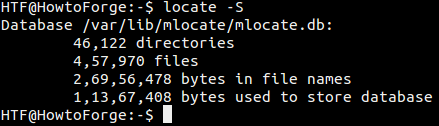
ロケート データベースに関する情報を表示する方法
ロケートが使用しているデータベースや、データベースに関するその他の統計情報を知りたい場合は、-S コマンド ライン オプションを使用します。
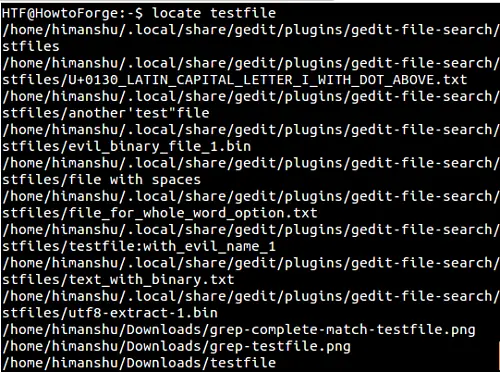
locateで正確なファイル名を検索する方法
デフォルトでは、locateでファイル名を検索するとき、渡した名前(NAME)は暗黙的に*NAME*で置き換えられる。 たとえば、ファイル名 ‘testfile’ を検索すると、*testfile* に一致するすべての名前が出力に生成されます:
しかし、’testfile’ に完全に一致する名前のファイルを検索する必要がある場合はどうでしょうか。 この場合、正規表現を使用する必要があります。これは、-r コマンドライン・オプションを使用して有効にすることができます。
locate -r /testfile$

正規表現に慣れていない場合は、こちらをご覧ください。
Conclusion
Locate にはさらに多くのオプションがありますが、ここで説明したものは、コマンドライン ユーティリティについての基本的な考えを提供し、始めるには十分なものでしょう。 まず、ここで説明したすべてのオプションを Linux マシンで試してみて、それからツールの man ページにある他のオプションに切り替えてみることをお勧めします
。