
>
>
>
>
Beginning with Data mining, uma nova e refinada abordagem de tamanho único a ser adotada com sucesso na predição de dados, é um método propício usado para análise de dados para descobrir tendências e conexões em dados que possam lançar interferência genuína.
Algumas ferramentas populares operadas em Data mining são as redes neurais artificiais (ANN), regressão logística, análise discriminante e árvores de decisão.
A árvore de decisão é a ferramenta mais notória e poderosa que é fácil de entender e rápida de implementar para a descoberta de conhecimento a partir de conjuntos de dados enormes e complexos.
Introdução
O número de teóricos e praticantes é regularmente re-polido técnicas a fim de tornar o processo mais rigoroso, adequado e econômico.
As árvores de decisão são usadas em teoria de decisão e estatística em larga escala. Estas também são ferramentas atraentes na mineração de dados, recuperação de informação, mineração de texto e reconhecimento de padrões na aprendizagem de máquinas.
Aqui, eu recomendaria a leitura do meu artigo anterior para habitar e aguçar o seu pool de conhecimentos em termos de árvores de decisão.
A essência das árvores de decisão prevalece na divisão dos conjuntos de dados em suas seções que indiretamente emergem uma árvore de decisão (invertida) tendo nós de raízes no topo. O modelo estratificado da árvore de decisão leva ao resultado final através da passagem sobre os nós das árvores.
Aqui, cada nó compreende um atributo (característica) que se torna a causa raiz de mais divisões na direção descendente.
Pode responder,
- Como decidir qual característica deve ser localizada no nó raiz,
- A característica mais precisa para servir como nós internos ou nós foliares,
- Como dividir árvore,
- Como medir a precisão da divisão da árvore e muito mais.
Existem alguns parâmetros fundamentais de divisão para abordar as consideráveis questões discutidas acima. E sim, no âmbito deste artigo, vamos cobrir a Entropia, Índice de Gini, Ganho de Informação e seu papel na execução da técnica de Árvores de Decisão.
Durante o processo de tomada de decisão, múltiplas características participam e torna-se essencial preocupar-se com a relevância e conseqüências de cada característica, atribuindo assim a característica apropriada no nó raiz e atravessando a divisão dos nós para baixo.
Movendo-se para a direção descendente leva a diminuições no nível de impureza e incerteza e rendimentos em melhor classificação ou divisão de elite em cada nó.
Para resolver o mesmo, medidas de divisão são usadas como Entropia, Ganho de Informação, Índice de Gini, etc.
Definindo Entropia
“O que é entropia? Nas palavras do Lyman, não é nada apenas a medida da desordem, ou medida de pureza. Basicamente, é a medida da impureza ou aleatoriedade nos pontos de dados.
Uma ordem alta de desordem significa um baixo nível de impureza, deixe-me simplificá-la. A entropia é calculada entre 0 e 1, embora dependendo do número de grupos ou classes presentes no conjunto de dados possa ser maior que 1, mas significa o mesmo significado, ou seja, maior nível de desordem.
Para uma interpretação simples, vamos limitar o valor da entropia entre 0 e 1,
Na imagem abaixo, uma forma em “U” invertido representa a variação da entropia no gráfico, o eixo x apresenta pontos de dados e o eixo y mostra o valor da entropia. A entropia é a menor (sem desordem) nos extremos (ambos extremos) e a máxima (desordem alta) no meio do gráfico.

“A entropia é um grau de aleatoriedade ou incerteza, por sua vez, satisfaz o alvo dos Data Scientists e modelos ML para reduzir a incerteza.”
O que é Ganho de Informação?
O conceito de entropia tem um papel importante no cálculo do Ganho de Informação.
Ganho de Informação é aplicado para quantificar qual característica fornece a máxima informação sobre a classificação baseada na noção de entropia, ou seja quantificando o tamanho da incerteza, desordem ou impureza, em geral, com a intenção de diminuir a quantidade de entropia iniciando do topo (nó raiz) para a base (nós de folhas).
O ganho de informação leva o produto das probabilidades da classe com um log com base 2 dessa classe de probabilidade, a fórmula para Entropia é dada abaixo:
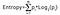
Aqui “p” denota a probabilidade de ser uma função da entropia.
Índice de Gini em Ação
Índice de Gini, também conhecido como impureza de Gini, calcula a quantidade de probabilidade de uma característica específica que é classificada incorretamente quando selecionada aleatoriamente. Se todos os elementos estão ligados a uma única classe, então ela pode ser chamada de pura.
Vamos perceber o critério do Índice de Gini, como as propriedades da entropia, o índice de Gini varia entre os valores 0 e 1, onde 0 expressa a pureza da classificação, ou seja, todos os elementos pertencem a uma classe especificada ou apenas uma classe existe lá. E 1 indica a distribuição aleatória dos elementos entre as várias classes. O valor 0,5 do Índice Gini mostra uma distribuição igual dos elementos sobre algumas classes.
Apesar de desenhar a árvore de decisão, as características que possuem o menor valor do Índice Gini seriam preferidas. Você pode aprender outro algoritmo baseado em árvores (Random Forest).
O Índice de Gini é determinado pela dedução da soma dos quadrados de probabilidades de cada classe de uma, matematicamente, o Índice de Gini pode ser expresso como:
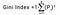
Onde Pi denota a probabilidade de um elemento ser classificado para uma classe distinta.
Classificação e algoritmo de Árvore de Regressão (CART) utiliza o método do Índice de Gini para originar partições binárias.
Além disso, algoritmos de árvore de decisão exploram o Ganho de Informação para dividir um nó e o Índice de Gini ou Entropia é a passagem para pesar o Ganho de Informação.
Índice de Gini versus Ganho de Informação
Vejam abaixo a discrepância entre o Índice de Gini e o Ganho de Informação,
- O Índice de Gini facilita as distribuições maiores tão fáceis de implementar enquanto que o Ganho de Informação favorece as distribuições menores tendo uma pequena contagem com múltiplos valores específicos.
- O método do Índice de Gini é usado pelos algoritmos CART, ao contrário dele, o Ganho de Informação é usado nos algoritmos ID3, C4.5.
- O índice de Gini opera sobre as variáveis alvo categóricas em termos de “sucesso” ou “falha” e realiza apenas divisão binária, ao contrário dessa divisão, o Information Gain calcula a diferença entre entropia antes e depois da divisão e indica a impureza em classes de elementos.
Conclusão
O índice de Gini e o Information Gain são usados para a análise do cenário em tempo real, e os dados são reais que são capturados a partir da análise em tempo real. Em numerosas definições, também tem sido mencionado como “impureza de dados” ou ” como os dados são distribuídos”. Então podemos calcular quais dados estão tomando menos ou mais parte na tomada de decisão.
Hoje eu acabo com nossas leituras superiores:
- O que é OpenAI GPT-3?
- Reliance Jio e JioMart: Estratégia de Marketing, Análise SWOT, e Ecossistema de Trabalho.
- 6 Principais Ramos da Inteligência Artificial(IA).
- Top 10 Grandes Tecnologias de Dados em 2020
- Como a Análise Está Transformando a Indústria Hoteleira
Oh ótimo, você chegou ao fim deste blog! Obrigado por ler!!!!!