
É recomendado entender o que é uma rede neural antes de ler este artigo. No processo de construção de uma rede neural, uma das escolhas que você pode fazer é qual a função de ativação a ser usada na camada oculta, bem como na camada de saída da rede. Este artigo discute algumas das escolhas.
Elementos de uma Rede Neural :-
Camada de Entrada :- Esta camada aceita recursos de entrada. Ela fornece informações do mundo externo para a rede, nenhum cálculo é realizado nesta camada, os nós aqui apenas passam as informações (características) para a camada oculta.
Camada oculta :- Os nós desta camada não são expostos ao mundo externo, eles são a parte da abstração fornecida por qualquer rede neural. A camada oculta realiza todo tipo de cálculo sobre os recursos inseridos através da camada de entrada e transfere o resultado para a camada de saída.
Camada de saída :- Esta camada traz as informações aprendidas pela rede para o mundo externo.
O que é uma função de ativação e por que usá-las?
Definição da função de ativação:- Função de ativação decide se um neurônio deve ou não ser ativado através do cálculo da soma ponderada e adicionando mais viés com ele. O propósito da função de ativação é introduzir não-linearidade na saída de um neurônio.
Explicação :-
Sabemos que a rede neural tem neurônios que trabalham em correspondência de peso, viés e sua respectiva função de ativação. Em uma rede neural, nós atualizaríamos os pesos e enviesamentos dos neurônios com base no erro no output. Este processo é conhecido como back-propagation. As funções de ativação tornam possível a retropropagação, pois os gradientes são fornecidos juntamente com o erro de atualização dos pesos e viés.
Por que precisamos de funções de ativação não linear :-
Uma rede neural sem uma função de ativação é essencialmente apenas um modelo de regressão linear. A função de ativação faz a transformação não-linear para o input tornando-o capaz de aprender e executar tarefas mais complexas.
Prova matemática :-
Suponha que temos uma rede neural como esta :-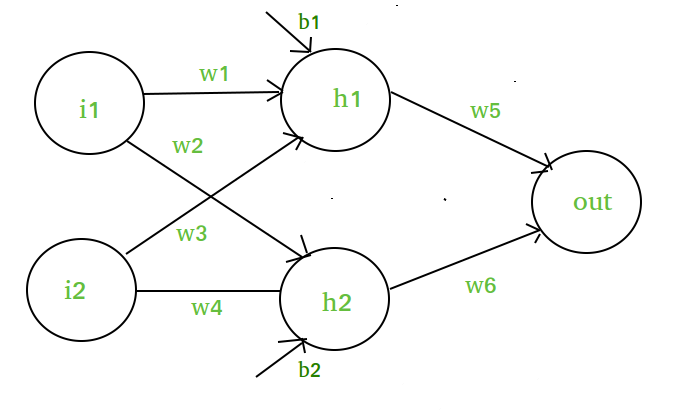 >
>
Elementos do diagrama :-
Camada oculta, ou seja camada 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Here,
- z(1) é a saída vetorizada da camada 1
- W(1) são os pesos vetorizados atribuídos aos neurônios
da camada oculta i.e. w1, w2, w3 e w4- X sejam as características de entrada vetorizada, ou seja i1 e i2
- b é o viés vetorizado atribuído aos neurônios na camada oculta
camada, ou seja, b1 e b2- a(1) é a forma vetorizada de qualquer função linear.
(Nota: Não estamos considerando função de ativação aqui)
Camada 2, ou seja camada de saída :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Cálculo na camada de saída:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Esta observação resulta novamente em uma função linear mesmo após a aplicação de uma camada oculta, portanto podemos concluir que, não importa quantas camadas ocultas fixamos na rede neural, todas as camadas se comportarão da mesma forma porque a composição de duas funções lineares é uma função linear em si. O neurônio não pode aprender apenas com uma função linear ligada a ele. Uma função de ativação não linear permitirá que ele aprenda pela diferença w.r.t error.
Hence we need activation function.
VARIANTS OF ACTIVATION FUNCTION :-
1). Função Linear :-
- Equação : Função linear tem a equação semelhante à de uma linha reta, ou seja, y = eixo
- Não importa quantas camadas temos, se todas são lineares por natureza, a função de ativação final da última camada não é nada mais que uma função linear da entrada da primeira camada.
- Gama : -inf to +inf
- Usos : A função de ativação linear é usada em apenas um lugar i.e. camada de saída.
- Questões : Se vamos diferenciar a função linear para trazer não-linearidade, o resultado não dependerá mais do input “x” e a função se tornará constante, ela não introduzirá nenhum comportamento inovador ao nosso algoritmo.
Por exemplo : O cálculo do preço de uma casa é um problema de regressão. O preço de uma casa pode ter qualquer valor grande/pequeno, por isso podemos aplicar a activação linear na camada de saída. Mesmo neste caso a rede neural deve ter qualquer função não linear em camadas ocultas.
2). Função Sigmoid :-
- É uma função que é plotada como gráfico em forma de ‘S’.
- Equação :
A = 1/(1 + e-x) - Natureza : Não-linear. Note que X valores estão entre -2 a 2, Y valores são muito íngremes. Isto significa que pequenas mudanças em x também trariam grandes mudanças no valor de Y.
- Intervalo de valores : 0 a 1
- Usos : Normalmente usado na camada de saída de uma classificação binária, onde o resultado ou é 0 ou 1, como o valor para a função sigmóide está entre 0 e 1 apenas assim, o resultado pode ser facilmente previsto como 1 se o valor for maior que 0,5 e 0 caso contrário.
3). Função Tanh :- A ativação que funciona quase sempre melhor que a função sigmóide é a função Tanh também conhecida como função Tangente Hiperbólica. É, na verdade, uma versão matematicamente deslocada da função sigmóide. Ambas são semelhantes e podem ser derivadas uma da outra.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Gama de valores :- -1 a +1
- Natureza :- não-linear
- Usos :- Normalmente usada em camadas ocultas de uma rede neural, pois seus valores estão entre -1 a 1, daí a média para a camada oculta sair ser 0 ou muito próxima dela, daí ajuda a centralizar os dados, aproximando a média de 0. Isto facilita muito a aprendizagem para a próxima camada.
- Equação :- A(x) = max(0,x). Ele dá uma saída x se x for positivo e 0 caso contrário.
- Faixa de valores :- [0, inf)
- Natureza :- não-linear, o que significa que podemos facilmente retropolar os erros e ter múltiplas camadas de neurônios sendo ativadas pela função ReLU.
- Usos :- ReLu é menos computacionalmente caro que tanh e sigmóide porque envolve operações matemáticas mais simples. De cada vez apenas alguns neurônios são ativados tornando a rede esparsa, tornando-a eficiente e fácil para computação.
4). RELU :- Significa unidade linear retificada. É a função de ativação mais amplamente utilizada. Implementada principalmente em camadas ocultas da rede neural.
Em palavras simples, RELU aprende muito mais rápido que a função sigmóide e Tanh.
5). Função Softmax :- A função softmax também é um tipo de função sigmóide mas é útil quando estamos tentando lidar com problemas de classificação.
- Natureza :- não-linear
- Usos :- Geralmente usado quando se tenta lidar com múltiplas classes. A função softmax apertaria os outputs de cada classe entre 0 e 1 e também dividiria pela soma dos outputs.
- Output:- A função softmax é idealmente utilizada na camada de output do classificador onde estamos realmente tentando atingir as probabilidades de definir a classe de cada input.
- A regra básica é se você realmente não sabe qual função de ativação usar, então simplesmente use RELU pois é uma função de ativação geral e é usada na maioria dos casos hoje em dia.
- Se o seu output é para classificação binária então, a função sigmoid é uma escolha muito natural para a camada de output.
CHOOSING THE RIGHT ACTIVATION FUNCTION
Pés Nota :-
A função de ativação faz a transformação não linear para o input, tornando-o capaz de aprender e executar tarefas mais complexas.