

Partendo dal Data mining, un nuovo raffinato approccio a taglia unica da adottare con successo nella predizione dei dati, è un metodo propizio usato per l’analisi dei dati per scoprire tendenze e connessioni nei dati che potrebbero lanciare interferenze genuine.
Alcuni strumenti popolari utilizzati nel Data mining sono le reti neurali artificiali (ANN), la regressione logistica, l’analisi discriminante e gli alberi di decisione.
L’albero di decisione è lo strumento più noto e potente che è facile da capire e veloce da implementare per la scoperta della conoscenza da enormi e complessi set di dati.
Introduzione
I teorici e i praticanti stanno regolarmente ripolverando le tecniche per rendere il processo più rigoroso, adeguato e conveniente.
Inizialmente, gli alberi di decisione sono usati nella teoria della decisione e nella statistica su larga scala. Sono anche strumenti convincenti nell’estrazione dei dati, nel recupero delle informazioni, nell’estrazione del testo e nel riconoscimento dei modelli nell’apprendimento automatico.
Qui, consiglierei di leggere il mio articolo precedente per soffermarsi e affinare il vostro pool di conoscenze in termini di alberi di decisione.
L’essenza degli alberi di decisione prevale nel dividere i set di dati nelle sue sezioni che indirettamente emergono un albero di decisione (invertito) con nodi di radici in alto. Il modello stratificato dell’albero di decisione porta al risultato finale attraverso il passaggio sui nodi degli alberi.
Qui, ogni nodo comprende un attributo (caratteristica) che diventa la causa principale di un’ulteriore suddivisione verso il basso.
Puoi rispondere,
- Come decidere quale caratteristica dovrebbe essere situata al nodo radice,
- La caratteristica più accurata per servire come nodi interni o nodi foglia,
- Come dividere l’albero,
- Come misurare la precisione della divisione dell’albero e molti altri.
Ci sono alcuni parametri di divisione fondamentali per affrontare le notevoli questioni discusse sopra. E sì, nell’ambito di questo articolo, copriremo l’Entropia, l’Indice di Gini, il Guadagno di Informazioni e il loro ruolo nell’esecuzione della tecnica degli Alberi di Decisione.
Durante il processo decisionale, partecipano più caratteristiche e diventa essenziale riguardare la rilevanza e le conseguenze di ogni caratteristica assegnando così la caratteristica appropriata al nodo principale e percorrendo la suddivisione dei nodi verso il basso.
Muovendosi verso la direzione verso il basso si ottiene una diminuzione del livello di impurità e di incertezza e si ottiene una migliore classificazione o una suddivisione dell’élite ad ogni nodo.
Per risolvere lo stesso, si usano misure di suddivisione come Entropia, Guadagno di informazione, Indice di Gini, ecc.
Definizione di Entropia
“Cos’è l’entropia? Nelle parole di Lyman, non è niente, solo la misura del disordine, o la misura della purezza. Fondamentalmente, è la misura dell’impurità o casualità nei punti di dati.
Un alto ordine di disordine significa un basso livello di impurità, lasciatemi semplificare. L’entropia è calcolata tra 0 e 1, anche se a seconda del numero di gruppi o classi presenti nell’insieme di dati potrebbe essere più grande di 1, ma significa lo stesso significato, cioè un livello più alto di disordine.
Per una semplice interpretazione, limitiamo il valore dell’entropia tra 0 e 1.
Nell’immagine sottostante, una forma a “U” rovesciata rappresenta la variazione dell’entropia sul grafico, l’asse x presenta i punti dei dati e l’asse y mostra il valore dell’entropia. L’entropia è la più bassa (nessun disordine) agli estremi (entrambe le estremità) e massima (alto disordine) al centro del grafico.

“L’entropia è un grado di casualità o incertezza, a sua volta, soddisfa l’obiettivo dei Data Scientists e dei modelli ML di ridurre l’incertezza.”
Che cos’è l’Information Gain?
Il concetto di entropia gioca un ruolo importante nel calcolo dell’Information Gain.
L’Information Gain viene applicato per quantificare quale caratteristica fornisce la massima informazione sulla classificazione basata sulla nozione di entropia, cioè quantificando la dimensione dell’incertezza, del disordine o dell’impurità, in generale, con l’intenzione di diminuire la quantità di entropia a partire dall’alto (nodo radice) verso il basso (nodi foglie).
Il guadagno di informazione prende il prodotto delle probabilità della classe con un log avente base 2 di quella probabilità di classe, la formula dell’entropia è data qui sotto:
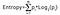
Qui “p” indica la probabilità che è una funzione dell’entropia.
Indice di Gini in azione
L’indice di Gini, noto anche come impurità di Gini, calcola la quantità di probabilità di un elemento specifico che viene classificato in modo errato quando viene selezionato casualmente. Se tutti gli elementi sono legati a una sola classe, allora può essere chiamata pura.
Percepiamo il criterio dell’indice di Gini, come le proprietà dell’entropia, l’indice di Gini varia tra i valori 0 e 1, dove 0 esprime la purezza della classificazione, cioè tutti gli elementi appartengono a una classe specifica o esiste solo una classe. E 1 indica la distribuzione casuale degli elementi in varie classi. Il valore di 0,5 dell’indice di Gini mostra un’equa distribuzione degli elementi su alcune classi.
Nel progettare l’albero di decisione, le caratteristiche che possiedono il minor valore dell’indice di Gini verrebbero preferite. Puoi imparare un altro algoritmo basato sull’albero (Random Forest).
L’indice di Gini è determinato deducendo la somma dei quadrati delle probabilità di ogni classe da uno, matematicamente, l’indice di Gini può essere espresso come:
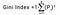
dove Pi indica la probabilità che un elemento sia classificato per una classe distinta.
L’algoritmo di classificazione e di regressione ad albero (CART) impiega il metodo dell’indice di Gini per creare suddivisioni binarie.
Inoltre, gli algoritmi ad albero di decisione sfruttano il guadagno di informazioni per dividere un nodo e l’indice di Gini o Entropia è il passaggio per pesare il guadagno di informazioni.
Indice di Gini vs Information Gain
Guardate qui sotto la discrepanza tra Indice di Gini e Information Gain,
- L’Indice di Gini facilita le distribuzioni più grandi così facili da implementare mentre l’Information Gain favorisce le distribuzioni minori con un piccolo conteggio con più valori specifici.
- Il metodo dell’indice di Gini è usato dagli algoritmi CART, al contrario di esso, il Guadagno d’informazione è usato negli algoritmi ID3, C4.5.
- L’indice di Gini opera sulle variabili target categoriche in termini di “successo” o “fallimento” ed esegue solo lo split binario, al contrario di quello Information Gain calcola la differenza tra l’entropia prima e dopo lo split e indica l’impurità nelle classi di elementi.
Conclusione
L’indice di Gini e Information Gain sono utilizzati per l’analisi dello scenario in tempo reale, e i dati sono reali che vengono catturati dall’analisi in tempo reale. In numerose definizioni, è stato anche menzionato come “impurità dei dati” o “come i dati sono distribuiti”. Così possiamo calcolare quali dati stanno prendendo meno o più parte nel processo decisionale.
Oggi finisco con le nostre letture migliori:
- Cos’è OpenAI GPT-3?
- Reliance Jio e JioMart: Strategia di marketing, analisi SWOT ed ecosistema di lavoro.
- 6 rami principali dell’intelligenza artificiale (AI).
- Top 10 Big Data Technologies nel 2020
- Come l’Analytics sta trasformando l’industria dell’ospitalità
Oh grande, sei arrivato alla fine di questo blog! Grazie per aver letto!!!!!