
TLDR: L’indicizzazione è solo un modo di raggruppare i documenti, dividendo le collezioni in gruppi per accelerare le prestazioni
Panoramica
Gli indici aumentano le prestazioni delle query e sono usati per le ricerche
L’idea di indicizzazione in MongoDB è simile all’indice di qualsiasi libro, aumentano la velocità di trovare una pagina. L’indice in MongoDB aumenta la velocità di trovare i documenti
Come funzionano gli indici?
Prima di tutto, cerchiamo di capire come si dichiara l’indice in MongoDB
collectionName.createIndex({field:value}) //for creating indexcollectionName.dropIndex({field:value}) //for removing index
Qui il campo è il “fieldName” che sarà indicizzato. “Value” può essere -1 o 1 o “text”.
Definisce il tipo di indice, 1 o -1 aumentano le prestazioni della query find() mentre “text” è usato per la ricerca.
1 e -1 danno l’ordine dell’indice. Ascendente = -1 & Discendente =1
Ora, come funzionano gli indici sotto il cofano?
Immaginate una collezione di utenti, ogni documento contiene varie informazioni, una delle quali è il punteggio.
Diciamo che vogliamo che tutti gli utenti ottengano 23 punti.
Quando non esiste un indice, MongoDB passa attraverso ogni documento per trovare il documento ricercato, questo è chiamato Collection scan, MongoDB ha un’abbreviazione per questo COLLSCAN (Questo è chiamato Table scan nei database relazionali)
Come possiamo ottimizzare questo?
Per ottimizzare questo possiamo creare una tabella con una colonna per il punteggio e un’altra colonna per i riferimenti che conterrà gli ID dei documenti con quel particolare punteggio. Ora abbiamo solo bisogno di scansionare quella tabella piuttosto che scansionare l’intero database. Questo è molto più veloce. Questo è esattamente ciò che è un indice.
Gli indici aiutano MongoDB a restringere il set di dati che dovrà scansionare. Questo si chiama Index Scan, MongoDB ha un’abbreviazione anche per questo IXNSCAN
Ecco una rappresentazione visiva di un indice di punteggio e la sua mappatura.
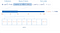
Il miglioramento delle prestazioni dell’indice è visibile solo quando il numero di documenti supera i 100K circa.
Puoi confrontarlo tu stesso confrontando due query una con un campo indicizzato e una senza indice
db.<collection name>.find(query).explain()
Sarà restituito un oggetto
oggetto.winingPlan.stage dirà il tipo di scansione COLLSCAN o IXNSCAN
ma non vi dirà il tempo impiegato nell’esecuzione
utilizzate il metodo explain(‘executionStat’) prima del metodo di interrogazione come find
db.<collection name>explain('executionStat').find(query)

executionTimeMillis vi dirà il tempo impiegato nell’esecuzione
Svantaggi dell’indice
Gli indici non sono liberi, Gli indici costano spazio. Gli indici possono aumentare la velocità di lettura ma ogni volta che qualcosa viene scritto, l’indice deve essere aggiornato per risolvere questo usiamo l’albero B- facciamo alcuni calcoli prima dell’inserimento in modo che sia più veloce.
B-Tree
Gli indici non sono una tabella di gruppi, concettualmente è in realtà un B-Tree (Binary Tree) non solo MongoDB, anche il database SQL usa B Tree per l’indicizzazione
questo video spiega meglio B Tree