
Si raccomanda di capire cos’è una rete neurale prima di leggere questo articolo. Nel processo di costruzione di una rete neurale, una delle scelte da fare è quale funzione di attivazione usare nello strato nascosto e nello strato di uscita della rete. Questo articolo discute alcune delle scelte.
Elementi di una rete neurale :-
Strato di input :- Questo strato accetta le caratteristiche di input. Fornisce informazioni dal mondo esterno alla rete, nessun calcolo viene eseguito in questo strato, i nodi qui passano solo le informazioni (caratteristiche) allo strato nascosto.
Strato nascosto :- I nodi di questo strato non sono esposti al mondo esterno, sono la parte dell’astrazione fornita da qualsiasi rete neurale. Lo strato nascosto esegue tutti i tipi di calcolo sulle caratteristiche inserite attraverso lo strato di input e trasferisce il risultato allo strato di output.
Strato di output :- Questo strato porta le informazioni apprese dalla rete al mondo esterno.
Cos’è una funzione di attivazione e perché usarla?
Definizione della funzione di attivazione:- La funzione di attivazione decide se un neurone deve essere attivato o meno calcolando la somma ponderata e aggiungendovi un bias. Lo scopo della funzione di attivazione è di introdurre la non linearità nell’uscita di un neurone.
Spiegazione :-
Sappiamo che la rete neurale ha neuroni che lavorano in corrispondenza di peso, bias e la loro rispettiva funzione di attivazione. In una rete neurale, aggiorniamo i pesi e i bias dei neuroni sulla base dell’errore in uscita. Questo processo è noto come back-propagation. Le funzioni di attivazione rendono possibile la retropropagazione poiché i gradienti sono forniti insieme all’errore per aggiornare i pesi e le polarizzazioni.
Perché abbiamo bisogno di funzioni di attivazione non lineari :-
Una rete neurale senza una funzione di attivazione è essenzialmente solo un modello di regressione lineare. La funzione di attivazione fa la trasformazione non lineare all’input rendendola capace di imparare ed eseguire compiti più complessi.
Prova matematica :-
Supponiamo di avere una rete neurale come questa :-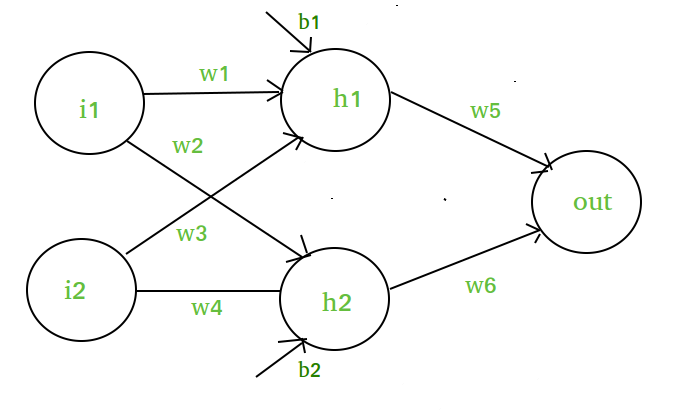
Elementi del diagramma :-
Strato nascosto cioè strato 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Qui,
- z(1) è l’uscita vettorializzata dello strato 1
- W(1) sono i pesi vettorializzati assegnati ai neuroni
dello strato nascosto i.e. w1, w2, w3 e w4- X sono le caratteristiche di ingresso vettorizzate cioè i1 e i2
- b è il bias vettoriale assegnato ai neuroni nello strato nascosto
cioè b1 e b2- a(1) è la forma vettoriale di qualsiasi funzione lineare.
(Nota: non stiamo considerando la funzione di attivazione qui)
Strato 2 cioè strato di uscita :-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Calcolo allo strato di uscita:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Questa osservazione risulta di nuovo in una funzione lineare anche dopo aver applicato uno strato nascosto, quindi possiamo concludere che, non importa quanti strati nascosti attacchiamo nella rete neurale, tutti gli strati si comporteranno allo stesso modo perché la composizione di due funzioni lineari è una funzione lineare stessa. Il neurone non può imparare solo con una funzione lineare collegata ad esso. Una funzione di attivazione non lineare gli permetterà di imparare secondo la differenza rispetto all’errore.
Quindi abbiamo bisogno della funzione di attivazione.
VARIANTI DELLA FUNZIONE DI ATTIVAZIONE :-
1). Funzione lineare :-
- Equazione: La funzione lineare ha l’equazione simile a quella di una linea retta cioè y = ax
- Non importa quanti strati abbiamo, se tutti sono di natura lineare, la funzione di attivazione finale dell’ultimo strato non è altro che una funzione lineare dell’input del primo strato.
- Range : -inf a +inf
- Usi : La funzione di attivazione lineare è usata solo in un posto cioè.e. strato di uscita.
- Problemi : Se differenzieremo la funzione lineare per portare la non-linearità, il risultato non dipenderà più dall’input “x” e la funzione diventerà costante, non introdurrà nessun comportamento innovativo al nostro algoritmo.
Per esempio : Il calcolo del prezzo di una casa è un problema di regressione. Il prezzo della casa può avere qualsiasi valore grande/piccolo, quindi possiamo applicare l’attivazione lineare allo strato di uscita. Anche in questo caso la rete neurale deve avere qualsiasi funzione non lineare agli strati nascosti.
2). Funzione Sigmoide :-
- È una funzione che viene tracciata come grafico a forma di ‘S’.
- Equazione :
A = 1/(1 + e-x) - Natura : Non lineare. Si noti che i valori di X sono compresi tra -2 e 2, i valori di Y sono molto ripidi. Questo significa che piccoli cambiamenti in x porterebbero anche grandi cambiamenti nel valore di Y.
- Intervallo di valori: da 0 a 1
- Usi: Di solito usato nello strato di uscita di una classificazione binaria, dove il risultato è o 0 o 1, come valore per la funzione sigmoide si trova solo tra 0 e 1 così, il risultato può essere previsto facilmente per essere 1 se il valore è maggiore di 0,5 e 0 altrimenti.
3). Funzione Tanh :- L’attivazione che funziona quasi sempre meglio della funzione sigmoide è la funzione Tanh conosciuta anche come funzione iperbolica tangente. E’ in realtà la versione matematicamente spostata della funzione sigmoide. Entrambi sono simili e possono essere derivati l’uno dall’altro.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Intervallo di valori :- da -1 a +1
- Natura :- non lineare
- Usi :- Di solito usato negli strati nascosti di una rete neurale in quanto i suoi valori sono compresi tra -1 e 1 quindi la media per lo strato nascosto risulta essere 0 o molto vicino ad essa, quindi aiuta a centrare i dati portando la media vicino a 0. Questo rende l’apprendimento per lo strato successivo molto più facile.
- Equazione :- A(x) = max(0,x). Dà un output x se x è positivo e 0 altrimenti.
- Range di valori :- [0, inf)
- Natura :- non lineare, il che significa che possiamo facilmente retropropagare gli errori e avere più strati di neuroni attivati dalla funzione ReLU.
- Usi :- ReLu è meno computazionalmente costoso di tanh e sigmoide perché comporta operazioni matematiche più semplici. Alla volta solo pochi neuroni sono attivati rendendo la rete rada e rendendola efficiente e facile da calcolare.
4). RELU :- Sta per Unità lineare rettificata. È la funzione di attivazione più utilizzata. Principalmente implementata negli strati nascosti della rete neurale.
In parole semplici, RELU impara molto più velocemente della funzione sigmoide e Tanh.
5). Funzione Softmax :- La funzione softmax è anche un tipo di funzione sigmoide ma è utile quando cerchiamo di gestire problemi di classificazione.
- Natura :- non lineare
- Usi :- Di solito usata quando si cerca di gestire classi multiple. La funzione softmax schiaccerebbe gli output per ogni classe tra 0 e 1 e dividerebbe anche per la somma degli output.
- Output:- La funzione softmax è idealmente usata nello strato di output del classificatore dove stiamo effettivamente cercando di ottenere le probabilità per definire la classe di ogni input.
- La regola di base è che se proprio non sai quale funzione di attivazione usare, allora usa semplicemente RELU perché è una funzione di attivazione generale ed è usata nella maggior parte dei casi in questi giorni.
- Se il tuo output è per la classificazione binaria allora, la funzione sigmoide è una scelta molto naturale per lo strato di output.
SCEGLIERE LA GIUSTA FUNZIONE DI ATTIVAZIONE
Nota: –
La funzione di attivazione fa la trasformazione non lineare dell’input rendendolo capace di imparare ed eseguire compiti più complessi.