
Het is aan te bevelen om te begrijpen wat een neuraal netwerk is voordat je dit artikel leest. Bij het bouwen van een neuraal netwerk is een van de keuzes die je moet maken welke activeringsfunctie je wilt gebruiken in de verborgen laag en in de uitvoerende laag van het netwerk. In dit artikel worden enkele van die keuzes besproken.
Elementen van een neuraal netwerk :-
Invoerlaag :- Deze laag accepteert invoerkenmerken. Het verstrekt informatie van de buitenwereld aan het netwerk, geen berekening wordt uitgevoerd in deze laag, knooppunten hier gewoon doorgeven van de informatie (kenmerken) aan de verborgen laag.
Verborgen laag :- Knooppunten van deze laag zijn niet blootgesteld aan de buitenwereld, ze zijn het deel van de abstractie die door een neuraal netwerk. De verborgen laag voert allerlei berekeningen uit op de kenmerken die door de inputlaag zijn ingevoerd en draagt het resultaat over aan de outputlaag.
Outputlaag :- Deze laag brengt de door het netwerk geleerde informatie naar de buitenwereld.
Wat is een activeringsfunctie en waarom moeten ze worden gebruikt?
Definitie van activeringsfunctie:- De activeringsfunctie beslist of een neuron al dan niet moet worden geactiveerd door de gewogen som te berekenen en daar de bias aan toe te voegen. Het doel van de activeringsfunctie is om niet-lineariteit in de output van een neuron te introduceren.
Uitleg :-
We weten dat neurale netwerken neuronen hebben die werken in overeenstemming met het gewicht, de bias en hun respectieve activeringsfunctie. In een neuraal netwerk zouden we de gewichten en biases van de neuronen bijwerken op basis van de fout aan de uitgang. Dit proces staat bekend als back-propagatie. Activeringsfuncties maken back-propagatie mogelijk omdat de gradiënten samen met de fout worden geleverd om de gewichten en biases bij te werken.
Waarom hebben we niet-lineaire activeringsfuncties nodig :-
Een neuraal netwerk zonder activeringsfunctie is in wezen niet meer dan een lineair regressiemodel. De activeringsfunctie zorgt voor de niet-lineaire transformatie van de invoer, waardoor het in staat is te leren en complexere taken uit te voeren.
Wiskundig bewijs :-
Voorstel dat we een neuraal netwerk als volgt hebben :-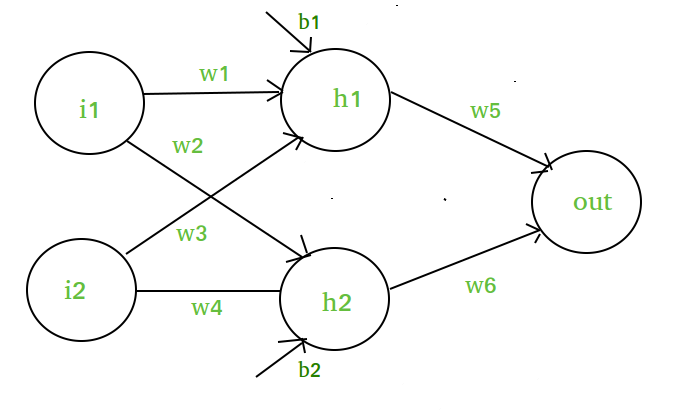
Elementen van het diagram :-
Verborgen laag, d.w.z. laag 1 :-
z(1) = W(1)X + b(1)
a(1) = z(1)
Hier,
- z(1) is de gevectoriseerde output van laag 1
- W(1) zijn de gevectoriseerde gewichten toegewezen aan neuronen
van verborgen laag i.w1, w2, w3 en w4- X de gevectoriseerde ingangseigenschappen zijn, d.w.z. i1 en i2
- b is de gevectoriseerde bias die aan neuronen in verborgen
laag wordt toegewezen, d.w.z. b1 en b2- a(1) is de gevectoriseerde vorm van een lineaire functie.
(Opmerking: wij beschouwen hier geen activeringsfunctie)
Laag 2 d.w.z. Uitgangslaag:-
// Note : Input for layer // 2 is output from layer 1z(2) = W(2)a(1) + b(2) a(2) = z(2)
Berekening bij Uitgangslaag:
// Putting value of z(1) herez(2) = (W(2) * ) + b(2) z(2) = * X + Let, = W = bFinal output : z(2) = W*X + bWhich is again a linear function
Deze observatie resulteert opnieuw in een lineaire functie, zelfs na het toepassen van een verborgen laag, vandaar dat we kunnen concluderen dat het niet uitmaakt hoeveel verborgen lagen we in een neuraal netwerk aanbrengen, alle lagen zullen zich op dezelfde manier gedragen omdat de samenstelling van twee lineaire functies zelf een lineaire functie is. Neuronen kunnen niet leren met slechts een lineaire functie eraan gekoppeld. Een niet-lineaire activeringsfunctie laat het leren volgens het verschil w.r.t. fout.
Hierom hebben wij activeringsfunctie nodig.
VARIËNTEN VAN ACTIVATIEFUNCTIE :-
1). Lineaire functie :-
- Vergelijking : Lineaire functie heeft een vergelijking die lijkt op die van een rechte lijn, d.w.z. y = ax
- Hoe veel lagen we ook hebben, als ze allemaal lineair van aard zijn, is de uiteindelijke activeringsfunctie van de laatste laag niets anders dan gewoon een lineaire functie van de input van de eerste laag.
- Bereik : -inf tot +inf
- Toepassingen : Lineaire activeringsfunctie wordt slechts op één plaats gebruikt, d.w.z. de uitvoerlaag.
- Als we de lineaire functie differentiëren om niet-lineariteit te brengen, zal het resultaat niet meer afhangen van de invoer “x” en de functie zal constant worden, het zal geen baanbrekend gedrag introduceren in ons algoritme.
Voorbeeld: Berekening van de prijs van een huis is een regressieprobleem. De prijs van een huis kan elke grote/kleine waarde hebben, dus kunnen we lineaire activering toepassen op de uitgangslaag. Zelfs in dit geval moet het neurale net een niet-lineaire functie in de verborgen lagen hebben.) Sigmoid Functie :-
- Het is een functie die wordt uitgezet als ‘S’ vormige grafiek.
- Vergelijking :
A = 1/(1 + e-x) - Aard : Niet-lineair. Merk op dat X waarden tussen -2 en 2 liggen, Y waarden zijn zeer steil. Dit betekent dat kleine veranderingen in x ook grote veranderingen in de waarde van Y teweegbrengen.
- Waardebereik : 0 tot 1
- Toepassingen : Gewoonlijk gebruikt in de uitvoerlaag van een binaire classificatie, waarbij het resultaat òf 0 òf 1 is, aangezien de waarde voor sigmoid-functie alleen tussen 0 en 1 ligt, zodat het resultaat gemakkelijk kan worden voorspeld als 1 als de waarde groter is dan 0,5 en anders 0.
3). Tanh-functie :- De activering die bijna altijd beter werkt dan de sigmoïdfunctie is de Tanh-functie, ook bekend als Tangent Hyperbool functie. Het is eigenlijk een wiskundig verschoven versie van de sigmoïde functie. Beide zijn vergelijkbaar en kunnen van elkaar worden afgeleid.
f(x) = tanh(x) = 2/(1 + e-2x) - 1ORtanh(x) = 2 * sigmoid(2x) - 1
- Value Range :- -1 tot +1
- Nature :- non-linear
- Uses :- Usually used in hidden layers of a neural network as it’s values lies between -1 to 1 hence the mean for the hidden layer comes out be 0 or very close to it, hence helps in centering the data by bringing mean close to 0. Dit maakt het leren voor de volgende laag veel gemakkelijker.
- Vergelijking :- A(x) = max(0,x). Het geeft een uitgang x als x positief is en anders 0.
- Waardebereik :- [0, inf)
- Aard :- niet-lineair, wat betekent dat we de fouten gemakkelijk kunnen backpropageren en meerdere lagen neuronen kunnen activeren door de ReLU-functie.
- Toepassingen :- ReLu is minder rekenintensief dan tanh en sigmoid omdat er eenvoudigere wiskundige bewerkingen mee gemoeid zijn. In een tijd slechts een paar neuronen worden geactiveerd waardoor het netwerk spaarzaam waardoor het efficiënt en gemakkelijk voor berekening.
4). RELU :- Staat voor Gelijkgerichte lineaire eenheid. Het is de meest gebruikte activeringsfunctie. Hoofdzakelijk geïmplementeerd in verborgen lagen van neurale netwerken.
In eenvoudige woorden, RELU leert veel sneller dan sigmoid en Tanh function.
5). Softmax-functie :- De softmax-functie is ook een soort sigmoid-functie, maar is handig wanneer we proberen classificatieproblemen te behandelen.
- Aard :- niet-lineair
- Gebruik :- Gewoonlijk gebruikt wanneer we proberen meerdere klassen te behandelen. De softmax-functie knijpt de uitgangen voor elke klasse tussen 0 en 1 en deelt ook door de som van de uitgangen.
- Uitgang:- De softmax-functie wordt idealiter gebruikt in de uitvoerlaag van de classificeerder waar we eigenlijk proberen de waarschijnlijkheden te bereiken om de klasse van elke invoer te definiëren.
- De basisvuistregel is dat als u echt niet weet welke activeringsfunctie u moet gebruiken, u gewoon RELU gebruikt, omdat dit een algemene activeringsfunctie is die tegenwoordig in de meeste gevallen wordt gebruikt.
- Als uw uitvoer voor binaire classificatie is, dan is sigmoid-functie zeer natuurlijke keus voor output layer.
HET GEBRUIKEN VAN DE RECHTE ACTIVATIEFUNCTIE
Foot Note :-
De activeringsfunctie doet de niet-lineaire transformatie naar de invoer waardoor het in staat is om te leren en meer complexe taken uit te voeren.