

Beginnend met Data mining, een onlangs verfijnde one-size-fits benadering die met succes kan worden toegepast bij het voorspellen van gegevens, is het een gunstige methode die wordt gebruikt voor gegevensanalyse om trends en verbanden in gegevens te ontdekken die echte storingen zouden kunnen veroorzaken.
Sommige populaire hulpmiddelen die in Data mining worden gebruikt, zijn kunstmatige neurale netwerken (ANN), logistieke regressie, discriminantanalyse en beslisbomen.
De beslisboom is het meest beruchte en krachtige hulpmiddel dat gemakkelijk te begrijpen en snel te implementeren is voor kennisontdekking uit enorme en complexe datasets.
Inleiding
Het aantal theoretici en beoefenaars herpolijsten regelmatig technieken om het proces strenger, adequater en kosteneffectiever te maken.
In eerste instantie worden beslisbomen op grote schaal gebruikt in de beslissingstheorie en statistiek. Dit zijn ook dwingende tools in Data mining, information retrieval, text mining, en patroonherkenning in machine learning.
Hier zou ik aanraden het lezen van mijn vorige artikel te blijven en uw kennis zwembad in termen van beslisbomen te scherpen.
De essentie van beslisbomen heerst in het verdelen van de datasets in zijn secties die indirect ontstaan een beslisboom (omgekeerd) met wortelknooppunten aan de top. Het gelaagde model van de beslisboom leidt tot het eindresultaat door de knooppunten van de bomen te passeren.
Hier omvat elk knooppunt een attribuut (kenmerk) dat de hoofdoorzaak wordt van verdere splitsing in de neerwaartse richting.
Kunt u antwoorden,
- Hoe te beslissen welk kenmerk moet worden gevestigd op de root node,
- Mooiste nauwkeurige kenmerk om te dienen als interne knooppunten of bladknooppunten,
- Hoe boom te verdelen,
- Hoe de nauwkeurigheid van het splitsen van boom en nog veel meer te meten.
Er zijn enkele fundamentele splitsingsparameters om de hierboven besproken aanzienlijke kwesties aan te pakken. En ja, in het rijk van dit artikel, zullen we betrekking hebben op de Entropie, Gini Index, Information Gain en hun rol in de uitvoering van de Beslissing Trees techniek.
Tijdens het proces van besluitvorming, meerdere functies deelnemen en het wordt essentieel om de relevantie en de gevolgen van elk kenmerk dus het toewijzen van de juiste functie aan de wortel knooppunt en de splitsing van knooppunten naar beneden traverseren.
Verplaatsing in neerwaartse richting leidt tot een afname van het niveau van onzuiverheid en onzekerheid en resulteert in een betere classificatie of elitesplitsing bij elk knooppunt.
Om hetzelfde op te lossen, worden splitsingsmaatregelen gebruikt zoals Entropie, Informatiewinst, Gini-index, enz.
Versnippering van Entropie
“Wat is entropie?” In de woorden van Lyman, is het niets anders dan de maat van wanorde, of maat van zuiverheid. In wezen is het de meting van de onzuiverheid of willekeur in de datapunten.
Een hoge orde van wanorde betekent een lage mate van onzuiverheid, laat ik het vereenvoudigen. Entropie wordt berekend tussen 0 en 1, hoewel afhankelijk van het aantal groepen of klassen aanwezig in de gegevensverzameling het groter dan 1 zou kunnen zijn, maar het betekent dezelfde betekenis, dat wil zeggen een hoger niveau van wanorde.
Voor een eenvoudige interpretatie beperken we de waarde van entropie tussen 0 en 1.
In de onderstaande afbeelding geeft een omgekeerde “U”-vorm de variatie van entropie op de grafiek weer, waarbij de x-as de gegevenspunten weergeeft en de y-as de waarde van entropie. De entropie is het laagst (geen wanorde) aan de uitersten (beide uiteinden) en het hoogst (grote wanorde) in het midden van de grafiek.

“Entropie is een mate van willekeur of onzekerheid, voldoet op zijn beurt aan het doel van Data Scientists en ML-modellen om de onzekerheid te verminderen.”
Wat is Information Gain?
Het begrip entropie speelt een belangrijke rol bij het berekenen van Information Gain.
Information Gain wordt toegepast om te kwantificeren welk kenmerk maximale informatie over de classificatie biedt op basis van het begrip entropie, d.w.z. door de grootte van onzekerheid, wanorde of onzuiverheid te kwantificeren, in het algemeen, met de bedoeling de hoeveelheid entropie af te laten nemen, beginnend vanaf de top (wortelknooppunt) naar de bodem (bladknooppunten).
De informatiewinst is het product van de waarschijnlijkheden van de klasse met een log die basis 2 heeft van de waarschijnlijkheid van die klasse, de formule voor Entropie is hieronder gegeven:
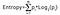
Hier geeft “p” de waarschijnlijkheid aan dat het een functie is van entropie.
Gini-index in actie
Gini-index, ook bekend als Gini-onzuiverheid, berekent hoe groot de kans is dat een bepaald kenmerk onjuist wordt ingedeeld wanneer het willekeurig wordt geselecteerd. Als alle elementen met één klasse verbonden zijn, kan men spreken van een zuivere klasse.
Laten we het criterium van de Gini-index eens bekijken, net als de eigenschappen van entropie, varieert de Gini-index tussen de waarden 0 en 1, waarbij 0 de zuiverheid van de classificatie uitdrukt, d.w.z. dat alle elementen tot een bepaalde klasse behoren of dat er slechts één klasse bestaat. En 1 wijst op de willekeurige verdeling van elementen over verschillende klassen. De waarde van 0,5 van de Gini Index toont een gelijke verdeling van elementen over sommige klassen.
Bij het ontwerpen van de beslissingsboom zouden de kenmerken die de minste waarde van de Gini Index bezitten, de voorkeur krijgen. U kunt leren een andere boom-gebaseerde algoritme (Random Forest).
De Gini-index wordt bepaald door de som van de kwadraten van de waarschijnlijkheden van elke klasse af te trekken van één. Wiskundig kan de Gini-index worden uitgedrukt als:
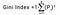
Waarbij Pi de waarschijnlijkheid weergeeft dat een element bij een bepaalde klasse wordt ingedeeld.
Classification and Regression Tree (CART)-algoritme maakt gebruik van de methode van de Gini-index om binaire splitsingen tot stand te brengen.
Beslissingsboomalgoritmen maken bovendien gebruik van informatiewinst om een knooppunt op te splitsen en Gini-index of Entropie is de manier om de informatiewinst te wegen.
Gini Index vs Information Gain
Lees hieronder de discrepantie tussen Gini Index en Information Gain,
- De Gini Index vergemakkelijkt de grotere verdelingen dus gemakkelijk te implementeren terwijl de Information Gain minder grote verdelingen met een kleine telling met meerdere specifieke waarden begunstigt.
- De methode van de Gini Index wordt gebruikt door CART algoritmen, in tegenstelling tot het, Information Gain wordt gebruikt in ID3, C4.5 algoritmen.
- Gini-index werkt op de categorische doelvariabelen in termen van “succes” of “mislukking” en voert alleen binaire splitsing uit, in tegenstelling tot dat Information Gain berekent het verschil tussen entropie voor en na de splitsing en geeft de onzuiverheid in klassen van elementen aan.
Conclusie
Gini-index en Information Gain worden gebruikt voor de analyse van het real-time scenario, en de gegevens zijn reëel die worden vastgelegd uit de real-time analyse. In talrijke definities is het ook vermeld als “onzuiverheid van gegevens” of “hoe de gegevens worden verdeeld. Dus we kunnen berekenen welke gegevens nemen minder of meer deel aan de besluitvorming.
Vandaag eindig ik met onze top leest:
- Wat is OpenAI GPT-3?
- Reliance Jio en JioMart: Marketing Strategie, SWOT Analyse, en Werkend Ecosysteem.
- 6 Belangrijke Takken van Kunstmatige Intelligentie (AI).
- Top 10 Big Data Technologieën in 2020
- Hoe Transformeert Analytics de Horeca
Oh geweldig, je hebt het tot het einde van deze blog geschopt! Bedankt voor het lezen!!!!!