
Internal Transcribed Spacers (ITS) er en region i det ribosomale transkript, der udskilles og nedbrydes under modningen. Deres sekvenser viser generelt større variation end den ribosomale sekvens, hvilket gør dem populære til fylogenetisk analyse og/eller identifikation af arter og stammer. Især for svampe er dette en populær teknik til identifikation, da identifikation på grundlag af morfologiske kendetegn er besværlig og ofte ikke fører til et korrekt resultat. Den anvendte region er normalt en kombination af ITS-sekvenser og ribosomale sekvenser og består oftest af en (delvis) 18S rRNA-sekvens (16S rRNA for prokaryoter), en internt transskriberet region (ITS1), hele sekvensen af 5,8s rRNA, en internt transskriberet region (ITS2) og en (delvis) sekvens af 28s rRNA. Mange ITS-sekvenser er tilgængelige på offentlige databaser, f.eks. NCBI og EBI.
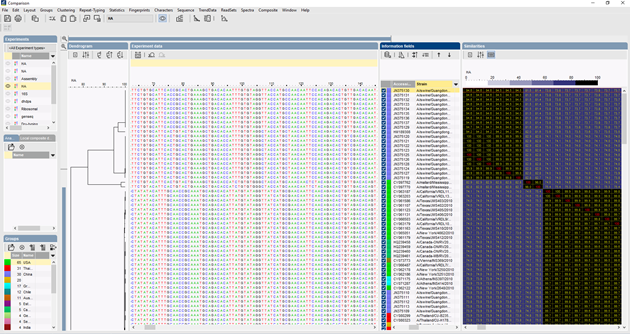
ITS-arbejdsgang for typning af ITS-sekvenser i BIONUMERICS-softwaren
I BIONUMERICS kan ITS-sekvenserne importeres i batch fra sporingsfiler ved hjælp af batch-sekvenssamlings-plugin’et. Referencesekvenser kan importeres fra offentlige databaser og/eller fra fasta- eller GenBank-filer.
Der kan anvendes flere algoritmer til at udføre en multipel alignment af sekvenserne, Needleman-Wunsch, Wilbur-Lipman og vores egen proprietære algoritme, der er udarbejdet hos Applied Maths. Manuel tilpasning af alignment er mulig. På baggrund af den multiple alignment kan der beregnes et clustering, der afspejler de fylogenetiske relationer mellem de analyserede sekvenser.
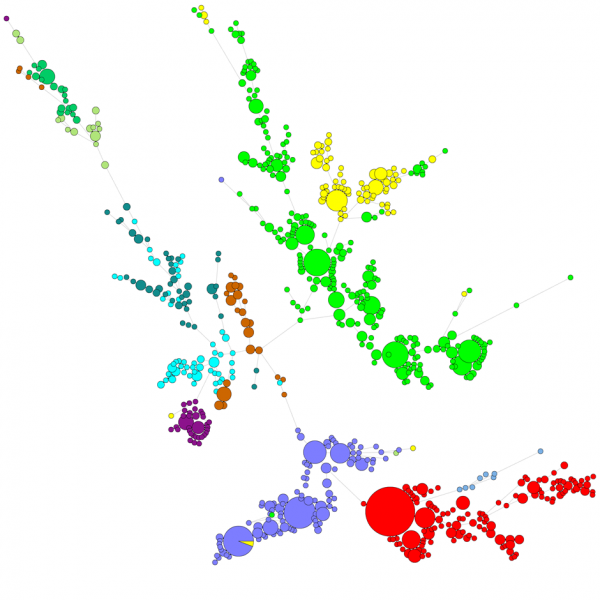
Ved sammenligning af et stort antal sekvenser giver et UPGMA- eller neighbor-joining dendrogram ikke et særlig godt overblik over dataene. I disse tilfælde giver et urodet træ en bedre løsning, i BIONUMERICS er det muligt at beregne minimal spanning trees, maximum likelihood trees og maximum parsimony trees med udgangspunkt i sekvensdata. Der kan defineres forskellige grupper for dataene, og disse grupper visualiseres i træerne, hvilket giver et godt overblik over de fylogenetiske relationer, de klynger, der er til stede i databasen, og også outliers. Figuren nedenfor viser et minimal spanning tree baseret på ITS-sekvenser, grupperne repræsenterer forskellige slægter.
ITS-sekvensen kan også bruges til at identificere ukendte organismer i forhold til en database. Med Classifiers and Identification-modulet kan brugeren oprette identifikationsprojekter, der indeholder identificerede stammer, og bruge disse til at identificere en ukendt stamme, og der vil blive tildelt en score baseret på ligheden sammen med pålideligheden af denne score. Brugeren har fuld kontrol over parametrene for sammenligning og cutoff-værdierne for identifikation.